用Golang实现四则运算 - 编译篇
Yui的编译过程分为以下几个阶段:
- 预处理
- 词法分析
- 语法分析
- 语义分析
- 将指令列表序列化为字节码
下面我们详细的了解一下每一个步骤的具体工作
预处理
预处理主要完成以下几个工作:
- 移除源代码中所有的注释信息
- 获取源代码中所有的
define代码,解析出define的key和value并把它们的映射关系保存在内存中 - 移除所有的define代码
- 移除所有的停用词
- 根据之前已经获取到的映射关系,把源代码中所有的被定义关键字替换为其相应的值
- 从源代码中解析出所有的表达式(多个表达式的情况下每个表达式用
{}进行包裹)
更多详细的信息可以查看预处理过程的源码进行进一步的了解。同时需要注意的是,预处理过程可能会生成多个表达式,而词法分析、语法分析、语义分析都是只针对单个表达式进行的。
词法分析
词法分析比较简单,只需要把表达式解析为token的列表,token包括以下几种类型:
- (
- )
- +
- -
- *
- /
- 浮点数
- 整数
token的解析使用正则表达式而不是手动的创建DFA和NFA,经过词法分析之后原始的字符串被分割为一个token列表,词法分析的源码在这里。
语法分析
语法分析的目的是把词法分析所得到的token列表转化为一棵抽象语法树(Abstract Syntax Tree,AST)。例如对于表达式
(1 + 2) * (3 - 4)
由于我们使用的是中缀表达式,所以应该生成一棵如下的AST
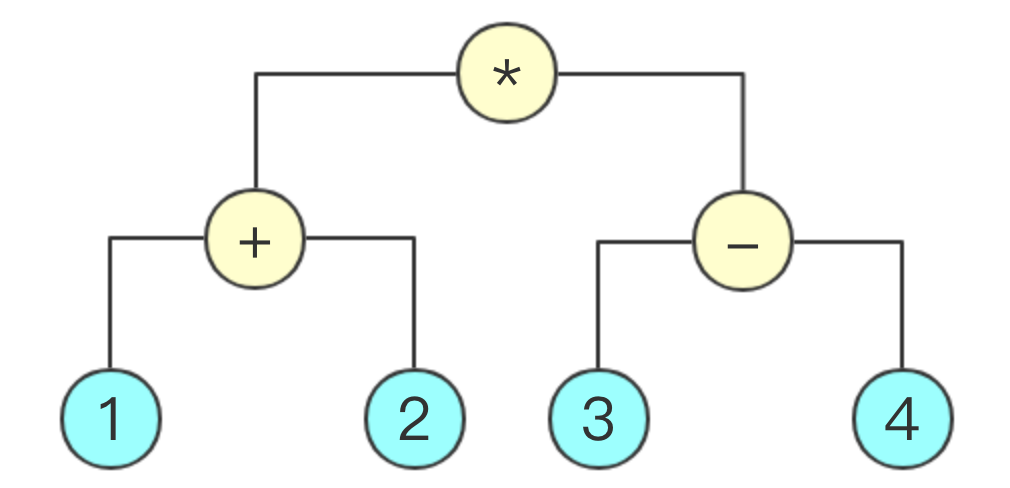
这里生成AST的难点在于运算规则的优先级,表达式运算有如下的三个优先级
- 括号:最高的优先级
- 乘除法:中等的优先级
- 加减法:最低的优先级
我们分别使用了不同的方法对应不同的优先级计算,计算加减法的方法在最外层,计算乘除法的方法在中间一层,最内部的方法解析括号内的表达式和负数。通过不断地读入token,这三个方法递归的执行,最终生成一棵AST。语法分析的源码在这里。
语义分析
在上一步我们已经得到了一棵AST,在语义分析中我们将遍历这棵树并且生成指令列表。我们使用递归的方式来遍历整棵树,在遍历的过程中我们把访问到的每个节点都创建为一条指令,然后把这条指令添加到指令列表中。
指令分为两类,一类是数值指令,一类是计算指令。所有的叶子节点都是数值指令,所有的内部节点都是计算指令。例如,对于上面那棵语法树,它可以生成如下的指令列表
PUSH 1
PUSH 2
PLUS
PUSH 3
PUSH 4
MINUS
MULTIPLY
语义分析的源码在这里。
将指令列表序列化为字节码
在上一步的语义分析中我们已经得到了最终的指令列表,但是指令本身需要经过序列化才可以进行保存和传输,下面我们看看如何把指令列表进行序列化。
由于在源码中可能有多个表达式,所以最终我们在语法分析结束后,得到的可能是包含多个表达式的指令列表。对于每一个表达式的指令列表,我们使用如下方式进行序列化
首先我们对指令进行编码,每一个指令都使用一个字节进行编码,具体编码如下:
PUSH 0x00 PLUS 0x01 MINUS 0x02 MULTIPLY 0x03 DIVIDE 0x04如果是操作指令,直接把这个指令的编码添加到字节数组中
如果是数值指令,除了把PUSH指令添加到字节数组之外,还要把对应的数值也序列化添加到字节数组中
- 首先判断数值是整数还是浮点数,在添加数值之前先使用一个字节表示接下来的数值类型(整型或浮点型)
- 整数和浮点数使用各自的编码方式进行序列化,再把数字序列化的结果添加到字节数组中
针对每一个表达式进行序列化的源码在这里。
在对每一个表达式进行了序列化之后,我们得到了一个字节数组的数组,接下来我们再把所有表达式的序列化结果整合起来
- 首先我们把MagicNumber放到字节数组的首部
- 取出一个表达式的序列化值,计算出这个字节数组的长度,然后将这个整型的长度转化为字节数组
- 把长度的值添加到字节数组中
- 把表达式本身添加到字节数组中
- 重复步骤 2 ~ 5 直到所有的表达式处理完毕
通过上面的方式我们生成一个大的字节数组,这就是我们最终生成的结果。
例如我们有两个表达式A和B,它们生成了两个字节数组A1和B1,那么我们可以构建如下的序列化结果
[MagicNumber][A1 Length Byte Array][A1][B1 Length Byte Array][B1]
在经过了上面这些步骤之后,我们最终把源码编译成了字节码。现在只需要把字节码写入到一个文件中,整个编译就完成了。
注:Yui还实现了从字节码到指令的转化过程,这是为了让目标文件中的指令更易读。此操作对应的命令为 dec,源码位于这里。