ANTLR (ANother Tool for Language Recognition)是一个强大的解析器生成器,用于读取、处理、执行或翻译结构化文本或二进制文档。它被广泛用于构建语言、工具和框架。ANTLR 根据语法定义生成解析器,解析器可以构建和遍历解析树。
安装 以 Linux 系统为例,我们首先 安装 Java17
~ java -version
java version "17.0.6" 2023-01-17 LTS
Java(TM) SE Runtime Environment (build 17.0.6+9-LTS-190)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.6+9-LTS-190, mixed mode, sharing)
随后我们下载 antlr4 的完整依赖包
wget https://www.antlr.org/download/antlr-4.13.0-complete.jar
并把依赖包添加到 Java 的 CLASSPATH 中,将以下命令添加到~/.zshrc文件中
export CLASSPATH="/home/raymond/Desktop/antlr4/antlr-4.13.0-complete.jar:$CLASSPATH"
之后我们就可以使用 antlr4 的 Tool 和 TestRig 了
~ java org.antlr.v4.Tool
ANTLR Parser Generator Version 4.13.0
-o ___ specify output directory where all output is generated
-lib ___ specify location of grammars, tokens files
-atn generate rule augmented transition network diagrams
-encoding ___ specify grammar file encoding; e.g., euc-jp
-message-format ___ specify output style for messages in antlr, gnu, vs2005
-long-messages show exception details when available for errors and warnings
-listener generate parse tree listener (default)
-no-listener don't generate parse tree listener
-visitor generate parse tree visitor
-no-visitor don't generate parse tree visitor (default)
-package ___ specify a package/namespace for the generated code
-depend generate file dependencies
-D<option>=value set/override a grammar-level option
-Werror treat warnings as errors
-XdbgST launch StringTemplate visualizer on generated code
-XdbgSTWait wait for STViz to close before continuing
-Xforce-atn use the ATN simulator for all predictions
-Xlog dump lots of logging info to antlr-timestamp.log
-Xexact-output-dir all output goes into -o dir regardless of paths/package
~ java org.antlr.v4.gui.TestRig
java org.antlr.v4.gui.TestRig GrammarName startRuleName
[-tokens] [-tree] [-gui] [-ps file.ps] [-encoding encodingname]
[-trace] [-diagnostics] [-SLL]
[input-filename(s)]
Use startRuleName='tokens' if GrammarName is a lexer grammar.
Omitting input-filename makes rig read from stdin.
可以在~/.zshrc中添加如下别名
alias antlr4='java org.antlr.v4.Tool'
alias grun='java org.antlr.v4.gui.TestRig'
后面就可以直接使用 antlr4 和 grun 命令了
一个简单的例子 我们从一个最简单的例子来看 antlr4,创建一个名为 Hello.g4 的文件并输入如下内容
1 2 3 4 5 grammar Hello; // 语法名称,必须要和文件名称一样 r : 'hello' ID ; // 表示匹配字符串hello和ID这个token,语法名称用小写字母定义 ID : [a-z]+ ; // ID这个token的定义只允许小写字母,词法名称用大写字母定义 WS : [ \t\r\n]+ -> skip ; // 忽略一些字符
随后执行antlr4 Hello.g4 -o code命令将语法文件转化为 Java 的代码,具体生成的文件如下
HelloBaseListener.java
Hello.interp
HelloLexer.interp
HelloLexer.java
HelloLexer.tokens
HelloListener.java
HelloParser.java
Hello.tokens
之后执行命令javac *.java将所有的 Java 代码进行编译,编译完了之后执行命令grun Hello r -tree并输入相关文本内容,之后输入 EOF(Linux 上面是 Ctrl + D)可以得到解析结果
➜ grun Hello r -tree
hello antlr
<EOF>
(r hello antlr)
其中 Hello 是语法文件的名称,r 则是语法的名称,-tree 表示以 lisp 语法展示语法,我们也可以使用-gui 选项展示语法树。
Visual Studio Code 提供了 antlr4 的 插件 ,可以方便的进行语法高亮和格式化等操作。IntelliJ Idea 也提供了 插件 ,具有快速生成代码、设置生成代码的参数以及查看语法树等功能。
使用 antlr4 构建一个计算器 首先我们创建一个 Calc.g4 文件,具体内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 grammar Calc; // 语法的名称,要和文件名称一致 calc: (expr)* EOF; // 一个或多个表达式 expr: BRACKET_L expr BRACKET_R // 圆括号 | (ADD | SUB)? (NUMBER | PERCENT_NUMBER) // 正负数字和百分数 | expr (MUL | DIV) expr // 乘除法 | expr (ADD | SUB) expr; // 加减法 PERCENT_NUMBER: NUMBER PERCENT; // 百分数 NUMBER: DIGIT (POINT DIGIT)?; // 小数 DIGIT: [0-9]+; // 数字 BRACKET_L: '('; // 左括号 BRACKET_R: ')'; // 右括号 ADD: '+'; SUB: '-'; MUL: '*'; DIV: '/'; PERCENT: '%'; POINT: '.'; WS: [ \t\r\n]+ -> skip; // 跳过空格换行等字符
执行命令antlr4 Calc.g4 -o code来生成代码,并将生成的代码放到code文件夹中。进入 code 文件夹,执行javac *.java命令编译代码。编译完代码之后,就可以执行测试程序了
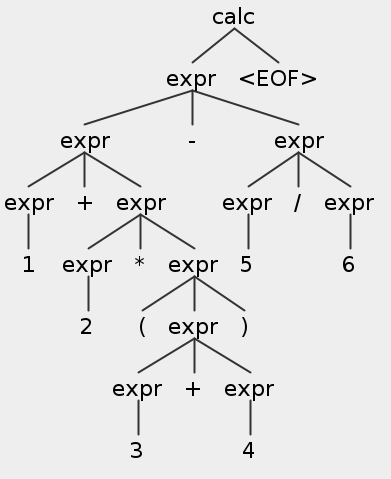
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ➜ grun Calc calc -tree 1 + 2 * (3 + 4) - 5 / 6 (calc (expr (expr (expr 1) + (expr (expr 2) * (expr ( (expr (expr 3) + (expr 4)) )))) - (expr (expr 5) / (expr 6))) <EOF>) ➜ grun Calc calc -tokens 1 + 2 * (3 + 4) - 5 / 6 [@0,0:0='1' ,<NUMBER>,1:0] [@1,2:2='+' ,<'+' >,1:2] [@2,4:4='2' ,<NUMBER>,1:4] [@3,6:6='*' ,<'*' >,1:6] [@4,8:8='(' ,<'(' >,1:8] [@5,9:9='3' ,<NUMBER>,1:9] [@6,11:11='+' ,<'+' >,1:11] [@7,13:13='4' ,<NUMBER>,1:13] [@8,14:14=')' ,<')' >,1:14] [@9,16:16='-' ,<'-' >,1:16] [@10,18:18='5' ,<NUMBER>,1:18] [@11,20:20='/' ,<'/' >,1:20] [@12,22:22='6' ,<NUMBER>,1:22] [@13,31:30='<EOF>' ,<EOF>,2:0] ➜ grun Calc calc -gui 1 + 2 * (3 + 4) - 5 / 6
第一个命令是生成 Lisp 风格的语法树,第二个命令是查看相应的 token,第三个命令生成的语法树如下所示
通过 Java 代码调用生成的 Lexer 和 Parser 还是以上面的例子为例,这次我们把词法分析和语法分析的内容分开来,分别创建CalcLexerRules.g4和Calc.g4文件,它们的内容分别如下
CalcLexerRules.g4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 lexer grammar CalcLexerRules; PERCENT_NUMBER: NUMBER PERCENT; NUMBER: DIGIT (POINT DIGIT)?; DIGIT: [0-9]+; BRACKET_L: '('; BRACKET_R: ')'; ADD: '+'; SUB: '-'; MUL: '*'; DIV: '/'; PERCENT: '%'; POINT: '.'; WS: [ \t\r\n]+ -> skip;
Calc.g4
1 2 3 4 5 6 7 8 9 10 grammar Calc; import CalcLexerRules; // 引入CalcLexerRules的词法规则 calc: (expr)* EOF; expr: BRACKET_L expr BRACKET_R | (ADD | SUB)? (NUMBER | PERCENT_NUMBER) | expr (MUL | DIV) expr | expr (ADD | SUB) expr;
创建这两个文件之后,执行命令antlr4 Calc.g4 -o code生成代码,antlr 会自动把 CalcLexerRules.g4 的内容引入进来。在生成代码的 code 文件夹下创建 Java 文件CalcTest.java,并使用 Java 代码调用生成的 Lexer 和 Parser 类中的方法
CalcTest.java
1 2 3 4 5 6 7 8 9 10 11 12 13 import org.antlr.v4.runtime.CharStreams;import org.antlr.v4.runtime.CommonTokenStream;import org.antlr.v4.runtime.tree.ParseTree;public class CalcTest { public static void main (String[] args) throws Exception { CalcLexer lexer = new CalcLexer (CharStreams.fromString("1 + 2 * (3 + 4) - 5 / 6" )); CommonTokenStream tokens = new CommonTokenStream (lexer); CalcParser parser = new CalcParser (tokens); ParseTree tree = parser.calc(); System.out.println(tree.toStringTree(parser)); } }
添加了如上的类之后,执行命令javac *.java编译源码文件,之后执行命令java CalcTest来运行 Java 代码,得到结果如下
(calc (expr (expr (expr 1) + (expr (expr 2) * (expr ( (expr (expr 3) + (expr 4)) )))) - (expr (expr 5) / (expr 6))) <EOF>)
运行结果和上面的 grun 的测试结果是一致的。
通过 Visitor 访问代码 上面我们使用 Java 代码调用了 CalcLexer 和 CalcParser 类,接下来我们实现一个 Visitor,通过 Visitor 来访问我们所需要访问的 AST 节点,并执行计算器的计算功能。
这里我们使用 Idea 的 ANTLR v4 插件来生成代码,上面的词法文件 CalcLexerRules.g4 不需要任何改变,而语法文件 Calc.g4 修改如下
1 2 3 4 5 6 7 8 9 10 11 12 13 grammar Calc; @header { package com.nosuchfield.calc.code; } import CalcLexerRules; // 引入词法分析文件 calc: (expr)* EOF # calculationBlock; expr: BRACKET_L expr BRACKET_R # expressionWithBr | sign = (ADD | SUB)? num = (NUMBER | PERCENT_NUMBER) # expressionNumeric | expr op = (MUL | DIV) expr # expressionMulOrDiv | expr op = (ADD | SUB) expr # expressionAddOrSub;
这里我们添加了@header标记,表示在生成代码的时候在代码头部生成我们所需要的内容,如上就是在代码头部放上了类的 package 声明。
我们还在每个语法后面使用井号#设置了一个标记名称,这个名称在生成 Visitor 代码的时候会生成相应名称的方法。此外我们还给表达式的参数设置了名称,例如 sign、num 和 op,这样当生成代码的时候,我们就可以用参数 num 取到 NUMBER 或者 PERCENT_NUMBER 的值。
我们在 Calc.g4 文件上右击并选择 Configure ANTLR 选项
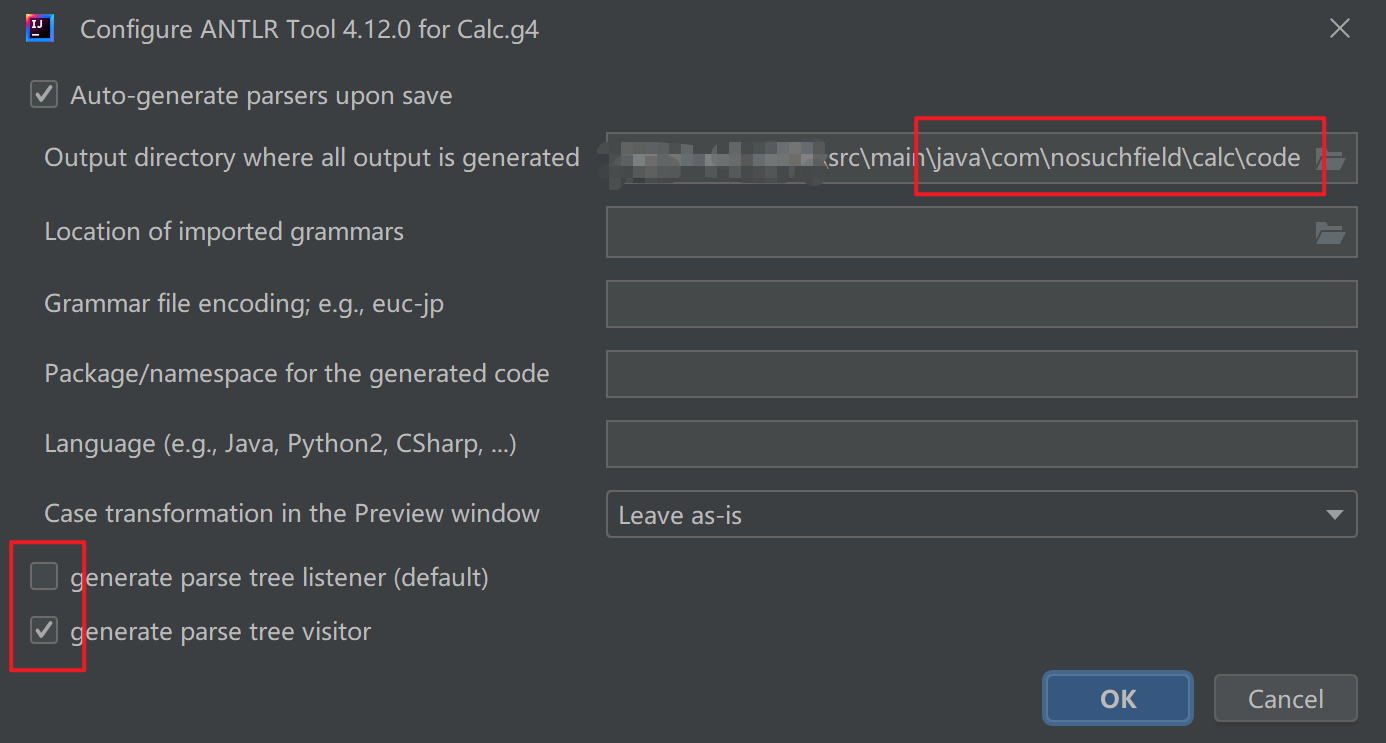
之后设置代码的生成目录为src/main/java/com/nosuchfield/calc/code,并且去掉生成 listener 的选项,同时选择生成 visitor 的选项
设置好了之后我们右击 Calc.g4 文件并右击选择 Generate ANTLR Recognizer 选项,即可在com/nosuchfield/calc/code文件夹下生成相关的代码
接下来我们自定义一个继承自 CalcBaseVisitor 类的 CalculateVisitor,具体如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 package com.nosuchfield.calc;import com.nosuchfield.calc.code.CalcBaseVisitor;import com.nosuchfield.calc.code.CalcLexer;import com.nosuchfield.calc.code.CalcParser;import org.antlr.v4.runtime.Token;import java.math.BigDecimal;import java.math.MathContext;import java.util.Objects;public class CalculateVisitor extends CalcBaseVisitor <BigDecimal> { private static final MathContext MATH_CONTEXT = MathContext.DECIMAL128; @Override public BigDecimal visitCalculationBlock (CalcParser.CalculationBlockContext ctx) { BigDecimal calcResult = null ; for (CalcParser.ExprContext expr : ctx.expr()) { calcResult = visit(expr); } return calcResult; } @Override public BigDecimal visitExpressionWithBr (CalcParser.ExpressionWithBrContext ctx) { return visit(ctx.expr()); } @Override public BigDecimal visitExpressionMulOrDiv (CalcParser.ExpressionMulOrDivContext ctx) { BigDecimal left = visit(ctx.expr(0 )); BigDecimal right = visit(ctx.expr(1 )); switch (ctx.op.getType()) { case CalcParser.MUL: return left.multiply(right, MATH_CONTEXT); case CalcParser.DIV: return left.divide(right, MATH_CONTEXT); default : throw new RuntimeException ("unsupported operator type" ); } } @Override public BigDecimal visitExpressionAddOrSub (CalcParser.ExpressionAddOrSubContext ctx) { BigDecimal left = visit(ctx.expr(0 )); BigDecimal right = visit(ctx.expr(1 )); switch (ctx.op.getType()) { case CalcParser.ADD: return left.add(right, MATH_CONTEXT); case CalcParser.SUB: return left.subtract(right, MATH_CONTEXT); default : throw new RuntimeException ("unsupported operator type" ); } } @Override public BigDecimal visitExpressionNumeric (CalcParser.ExpressionNumericContext ctx) { BigDecimal numeric = numberOrPercent(ctx.num); if (Objects.nonNull(ctx.sign) && ctx.sign.getType() == CalcLexer.SUB) { return numeric.negate(); } return numeric; } private BigDecimal numberOrPercent (Token num) { String numberStr = num.getText(); switch (num.getType()) { case CalcLexer.NUMBER: return new BigDecimal (numberStr); case CalcLexer.PERCENT_NUMBER: return new BigDecimal (numberStr.substring(0 , numberStr.length() - 1 ).trim()) .divide(BigDecimal.valueOf(100 ), MATH_CONTEXT); default : throw new RuntimeException ("unsupported number type" ); } } }
在自定义的 Visitor 中我们实现了计算逻辑,可以看到,这里重写了类 CalcBaseVisitor 的 5 个方法,分别对应了语法文件中的 5 个标记以及它们定义的名称,而属性的定义如 num 则对应了方法中入参的属性。以 expressionNumeric 语法为例,它对应的了方法 visitExpressionNumeric,我们可以通过方法入参 ExpressionNumericContext 取到 sign 和 num 属性,之后通过这两个属性来定义数字的值。而 expressionMulOrDiv 语法就是通过 op 取到运算符,之后对两边的数字根据运算符来进行相应的计算。
有了 visitor 之后,我们用一个测试类来测试计算结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 package com.nosuchfield.calc;import com.nosuchfield.calc.code.CalcLexer;import com.nosuchfield.calc.code.CalcParser;import org.antlr.v4.runtime.CharStream;import org.antlr.v4.runtime.CharStreams;import org.antlr.v4.runtime.CommonTokenStream;import org.junit.Test;import java.math.BigDecimal;import static junit.framework.TestCase.assertEquals;public class TestCalculate { @Test public void testCalculate () { String[][] sources = new String [][]{ {"1 + 2" , "3" }, {"3 - 2" , "1" }, {"2 * 3" , "6" }, {"6 / 3" , "2" }, {"6 / (1 + 2)" , "2" }, {"50%" , "0.5" }, {"100 * 30%" , "30.0" }, {"1 + 2 * (3 - 4) / 5" , "0.6" }, {"-8 + 8 * 2 - 8" , "0" } }; for (String[] source : sources) { String input = source[0 ].trim(); BigDecimal result = new BigDecimal (source[1 ].trim()); assertEquals(calculate(input), result); } } private BigDecimal calculate (String expression) { CharStream cs = CharStreams.fromString(expression); CalcLexer lexer = new CalcLexer (cs); CommonTokenStream tokens = new CommonTokenStream (lexer); CalcParser parser = new CalcParser (tokens); CalcParser.CalcContext context = parser.calc(); CalculateVisitor visitor = new CalculateVisitor (); return visitor.visit(context); } }
可以看到,我们构建的计算器已经成功的计算出了正确结果。
ANTLR4 的工作流程 在上面的例子中我们已经了解到,使用 antlr4 的一般流程如下
书写 antlr4 的词法和文法规则 使用 antlr4 的生成工具处理写好的规则,以生成指定语言的 Lexer 和 Parser 代码 调用生成的 Lexer 和 Parser 类,书写相应的逻辑代码,将原始输入文本转化为一个抽象语法树 使用 antlr4 的 visitor 来解析语法树,实现各种功能 实际上,除了 visitor 之外,antlr4 还提供了另一种解析语法树方式,叫做 Listener。Listener 是 antlr4 默认解析语法树的方式,它和 visitor 一样都可以实现对 ParseTree 的解析。如果开启了 visitor 或 listener,那么 antlr4 除了会生成 Lexer 和 Parser 代码,还会生成相应的 Visitor 和 Listener 代码。
Listener 和 Visitor 区别如下注
Listener Visitor 是否访问所有节点 访问所有节点 只访问手动指定的节点 访问节点方式 通过 enter 和 exit 方法 通过 visit 方法 方法是否有返回值 没有返回值 有返回值
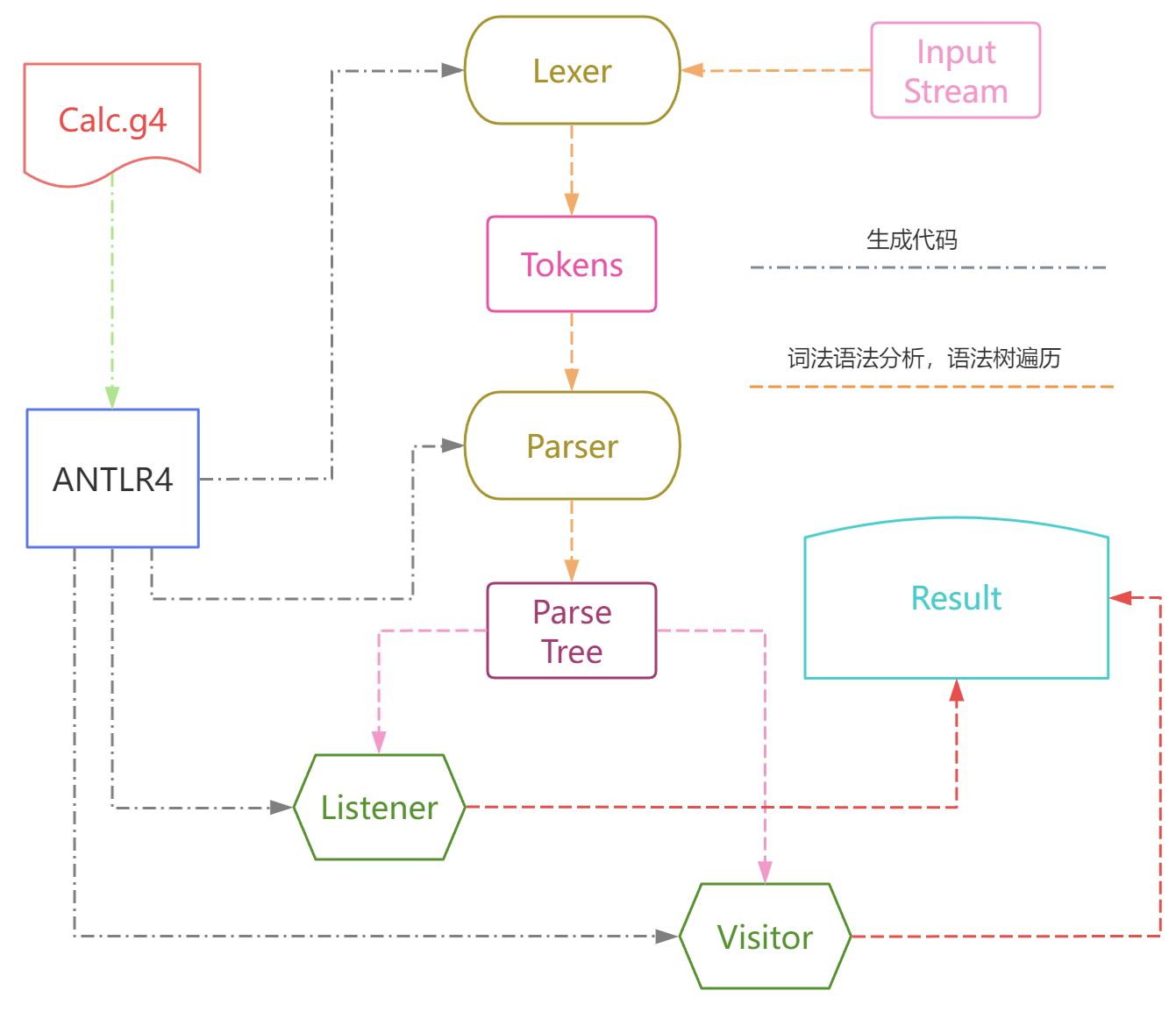
了解了 Listener 和 Visitor 的区别之后,我们可以总结出 antlr4 的大致工作流程如下
如上左边的点线流程 代表了通过 ANTLR4,将原始的.g4规则转化为 Lexer、Parser、Listener 和 Visitor。右边的虚线流程 代表了将原始的输入流通过 Lexer 转化为 Tokens,再将 Tokens 通过 Parser 转化为语法树,最后通过 Listener 或 Visitor 遍历 ParseTree 得到最终结果。
解析 CSV 文件 我们已经使用 Visitor 构建过一个计算器,接下来我们使用 Listener 实现对 CSV 的解析。Comma-separated values (CSV) 文件是一种使用英文逗号 , 来分割字段的文件格式。文件分为多行,每行又被逗号分割为多列,第一行的内容可以当作字段的名称。下面是一个例子
省份,城市,区县,描述
江苏,南京,雨花台,外包大道
浙江,杭州,西湖,太美丽啦!西湖
,上海,黄浦,“as it says: ”“hello, shanghai”“”
分析这个格式,首先是一行头部,之后跟着多行数据,因此可以很容易的得出如下的语法规则
csv: hdr row*;
而头部也是一样的数据格式,因此有如下规则
hdr: row;
数据是一些由逗号分割的字段,因此可以定义数据如下。其中\n是 Mac 和 Linux 的换行符,\r\n则是 Windows 下的换行符,因此\r是可选的
row: field (',' field)* '\r'? '\n';
接下来只需要定义 field 的词法即可,因为换行和逗号都是 CSV 中的格式符号,不允许在字符中存在。因此可以很容易的得到
field: ~[\n,\r]+;
~代表取反,也就是除了换行和逗号之外的其它多个字符。
有了上面这个规则还不够,因为 CSV 标准规定了,如果有特殊字符,可以用双引号包起来。例如一个逗号如果被包含在双引号里面,那么就是一个字段的组成部分而不是字段的分隔符。如果双引号包裹的内容中又有双引号,那么需要将这个字段内部的双引号用两个双引号进行替代。
field: '"' ('""' | ~'"')* '"';
如上规则表示用双引号包裹的内容,可以是两个双引号或者除了单个双引号之外的其它任意内容。
CSV 还允许空字段
field: ;
整理如上规则,并添加包配置和相关的标记
1 2 3 4 5 6 7 8 9 10 11 12 13 grammar Csv; @header { package com.nosuchfield.csv.code; } csv: hdr row*; hdr: row; row: field (',' field)* '\r'? '\n'; field: TEXT # text | STRING # string | # empty; TEXT: ~[\n,\r]+; STRING: '"' ('""' | ~'"')* '"';
之后配置代码生成目录为com/nosuchfield/csv/code,并去掉生成 Visitor 的选项,勾选生成 Listener 的选项,使用 antlr4 生成代码,生成的 Java 代码如下
CsvBaseListener.java
CsvLexer.java
CsvListener.java
CsvParser.java
可以看到除了 Lexer 和 Parser,还生成了相应的 Listener 代码。我们创建一个继承自 CsvBaseListener 的类如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 package com.nosuchfield.csv;import com.nosuchfield.csv.code.CsvBaseListener;import com.nosuchfield.csv.code.CsvParser;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;public class CsvListener extends CsvBaseListener { private final List<Map<String, String>> rows = new ArrayList <>(); private List<String> header; private List<String> row; @Override public void enterRow (CsvParser.RowContext ctx) { row = new ArrayList <>(); } @Override public void exitText (CsvParser.TextContext ctx) { row.add(ctx.TEXT().getText()); } @Override public void exitString (CsvParser.StringContext ctx) { String field = ctx.STRING().getText(); field = field.substring(1 , field.length() - 2 ); field = field.replaceAll("\"\"" , "\"" ); row.add(field); } @Override public void exitEmpty (CsvParser.EmptyContext ctx) { row.add("" ); } @Override public void exitRow (CsvParser.RowContext ctx) { if (ctx.getParent() instanceof CsvParser.HdrContext) { header = row; return ; } Map<String, String> data = new HashMap <>(); for (int i = 0 ; i < row.size(); i++) { data.put(header.get(i), row.get(i)); } rows.add(data); } public List<Map<String, String>> getRows () { return rows; } }
如上的 Listener 在进入行的时候初始化容器,在退出字段的时候将字段的数据保存到容器中,并在退出行的时候最终保存所有的字段。我们通过 Lexer 和 Parser 来解析上面的 CSV 数据,最终生成一个 ParseTree,并调用 Listener 遍历 ParseTree 来解析生成的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public void testCsv () throws IOException { CsvLexer lexer = new CsvLexer (CharStreams.fromFileName("src/main/resources/csv/city.csv" )); CommonTokenStream tokens = new CommonTokenStream (lexer); CsvParser parser = new CsvParser (tokens); ParseTree tree = parser.csv(); System.out.println(tree.toStringTree(parser)); ParseTreeWalker parseTreeWalker = new ParseTreeWalker (); CsvListener listener = new CsvListener (); parseTreeWalker.walk(listener, tree); System.out.println(listener.getRows()); }
执行上面的代码得到结果如下,可以看到完整的打印出了 CSV 的数据
(csv (hdr (row (field 省份) , (field 城市) , (field 区县) , (field 描述) \r \n)) (row (field 江苏) , (field 南京) , (field 雨花台) , (field 外包大道) \r \n) (row (field 浙江) , (field 杭州) , (field 西湖) , (field 太美丽啦!西湖) \r \n) (row field , (field 上海) , (field 黄浦) , (field “as it says: ”“hello, shanghai”“”) \r \n))
[{省份=江苏, 描述=外包大道, 城市=南京, 区县=雨花台}, {省份=浙江, 描述=太美丽啦!西湖, 城市=杭州, 区县=西湖}, {省份=, 描述=as it says: “hello, shanghai”, 城市=上海, 区县=黄浦}]
通过 Listener 构建一个计算器 在上面的例子中,我们已经使用了 Visitor 实现了一个计算器,实际上通过 Listener 也可以实现相同的功能。在 Visitor 中我们通过方法的返回值来存储计算结果,在 Listener 中方法没有返回值,那我们就需要通过另一种方式来进行计算并存储计算结果 —— 栈。
还是使用上面的词法分析和语法分析规则,这次我们勾选生成 Listener 选项,之后再次生成代码,这次会生成CalcListener接口和CalcBaseListener类,我们实现一个继承自CalcBaseListener的类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 public class CalculateListener extends CalcBaseListener { private static final MathContext MATH_CONTEXT = MathContext.DECIMAL128; private Stack<BigDecimal> stack; private BigDecimal result; @Override public void enterCalculationBlock (CalcParser.CalculationBlockContext ctx) { stack = new Stack <>(); } @Override public void exitCalculationBlock (CalcParser.CalculationBlockContext ctx) { result = stack.pop(); } @Override public void exitExpressionMulOrDiv (CalcParser.ExpressionMulOrDivContext ctx) { BigDecimal x = stack.pop(); BigDecimal y = stack.pop(); BigDecimal z; switch (ctx.op.getType()) { case CalcLexer.MUL: z = y.multiply(x, MATH_CONTEXT); break ; case CalcLexer.DIV: z = y.divide(x, MATH_CONTEXT); break ; default : throw new RuntimeException ("unsupported operator type" ); } stack.push(z); } @Override public void exitExpressionAddOrSub (CalcParser.ExpressionAddOrSubContext ctx) { BigDecimal x = stack.pop(); BigDecimal y = stack.pop(); BigDecimal z; switch (ctx.op.getType()) { case CalcLexer.ADD: z = y.add(x, MATH_CONTEXT); break ; case CalcLexer.SUB: z = y.subtract(x, MATH_CONTEXT); break ; default : throw new RuntimeException ("unsupported operator type" ); } stack.push(z); } @Override public void exitExpressionNumeric (CalcParser.ExpressionNumericContext ctx) { BigDecimal numeric = numberOrPercent(ctx.num); if (Objects.nonNull(ctx.sign) && ctx.sign.getType() == CalcLexer.SUB) { numeric = numeric.negate(); } stack.push(numeric); } private BigDecimal numberOrPercent (Token num) { String numberStr = num.getText(); switch (num.getType()) { case CalcLexer.NUMBER: return new BigDecimal (numberStr); case CalcLexer.PERCENT_NUMBER: return new BigDecimal (numberStr.substring(0 , numberStr.length() - 1 ).trim()) .divide(BigDecimal.valueOf(100 ), MATH_CONTEXT); default : throw new RuntimeException ("unsupported number type" ); } } public BigDecimal getResult () { return result; } }
上面的代码和 Visitor 非常相似,区别在于针对加减法和乘除法的计算,Visitor 是直接拿方法参数计算,并将结果作为返回值返回。而 Listener 是从栈的顶部取出两个元素进行计算,并将计算结果压回栈。
如果你了解方法调用的一般方式,就应该知道其实方法调用的一般方式也是通过栈来存储方法的入参和出参的。在方法调用前,将方法入参的值压入栈中,之后运行方法,如果方法中还有方法调用,继续将入参压入栈。当方法开始执行时,将方法的入参弹出,等到方法执行完毕,将执行完毕的方法返回值压入栈,如此往复就形成了方法调用。
因此我们可以知道,计算 Visitor 和 Listener 的逻辑基本一致,都是使用栈来存储计算的数值和计算的结果。区别在于 Visitor 的值是存储在当前运行线程的栈上的,如果值过多,可能因为栈空间不够导致 StackOverflow 错误。而 Listener 的值是保存在我们自定义的位于堆内存的栈数据结构上的,可以存储更多的数据内容。
完整的代码位于https://github.com/RitterHou/test-antlr4
参考 ANTLR 4 权威指南 语法解析器 ANTLR4 从入门到实践 从一个小例子理解 Antlr4 Antlr4 系列(二):实现一个计算器 ANTLR 使用——以表达式语法为例 Antlr4 教程