defdata_equals(self, data): return self.data == data
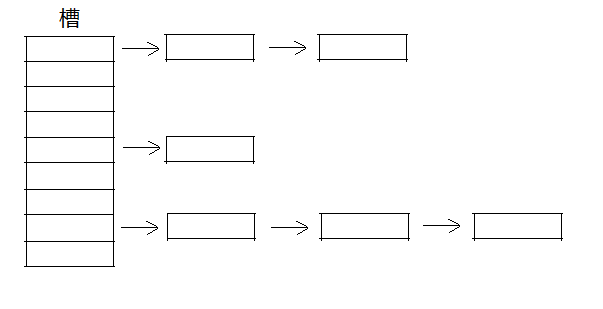
classHashTable(object): def__init__(self): self.value = [None] * num
definsert(self, data): if self.search(data): returnTrue
i = data % num node = Node(data) if self.value[i] isNone: self.value[i] = node returnTrue else: head = self.value[i] while head.get_next() isnotNone: head = head.get_next() head.set_next(node) returnTrue
defsearch(self, data): i = data % num if self.value[i] isNone: returnFalse else: head = self.value[i] while head andnot head.data_equals(data): head = head.get_next() if head: return head else: returnFalse
defdelete(self, data): if self.search(data): i = data % num if self.value[i].data_equals(data): self.value[i] = self.value[i].get_next() else: head = self.value[i] whilenot head.get_next().data_equals(data): head = head.get_next() head.set_next(head.get_next().get_next()) returnTrue else: returnFalse
defecho(self): i = 0 for head in self.value: printstr(i) + ':\t', if head isNone: printNone, else: while head isnotNone: printstr(head.get_data()) + ' ->', head = head.get_next() printNone, print'' i += 1 print''