什么是 DHT
Distributed hash table (DHT),中文翻译叫做分布式哈希表。DHT 是 P2P 网络和分布式存储中常见的一种技术,它本质上的思想是把数据(一般是键值对,即 Key-Value)根据其哈希值(这里指 Key 的哈希值)存储到网络上不同的节点中。DHT 只是一种指导思想,具体实现还有很多的细节需要考虑,常见的 DHT 实现有 Chord 和 Kademlia,其中 Chord 中使用了一致性哈希来实现分布式哈希表,下面我们详细了解一下一致性哈希。
在一个分布式系统中,我们对所有的数值和节点使用相同的哈希函数。我们构建一个线段,左侧代表了哈希函数所能产生的最小值,右侧代表此哈希函数所能生成的最大值。在构建了一个这样的线段之后,我们把线段首尾相连,形成一个圆环,此时该哈希函数的任意结果在该圆环上都能找到一个对应的位置。
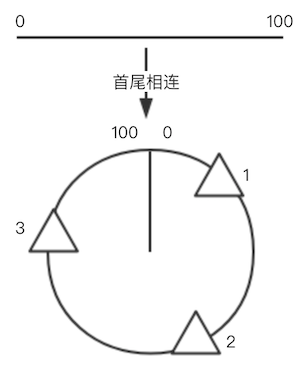
例如对于上面这个例子,这个分布式系统中存在三个节点,每个节点的位置通过计算其本身 node_id(例如 ip+port+process_id)的哈希函数得到,使用相同的哈希函数计算数据的哈希值,把数据保存在一致性哈希环的对应的位置。在哈希环上,从一个节点开始顺时针滑动,直到下一个节点之前的弧度上的所有的数据都保存当前节点之中。除了记录数据之外,每一个节点还需要记录其前一个节点和后一个节点的位置。
一致性哈希的路由
最简单的路由方式就是遍历,我们从指定节点开始进行路由,如果当前节点不存在该数据则继续到下一个节点中进行查找,一直到找到该数据或者确定该数据不存在为止。这种方式比较低效,在节点数量较多时查找一次数据可能需要耗费相当长的时间。
解决办法是使用路由表,即当前节点不仅仅存储前后节点的信息,还会存储更多节点的信息,这样在查找时可以更快的路由到指定的节点。关键问题在于存储多少节点的信息比较合适,存储少了查找效率无法得到显著提升,存储多了会占用更多的存储空间且在某个节点新增或删除时需要更多的节点更新其路由表。下面描述了一种比较好的路由表设计方法。
我们首先算得哈希环的比特位长度 m(例如哈希环最大值为 1000,因为 (29 = 512) < 1000 < (210 = 1024),所以我们得到此哈希环的比特位长度 m 为 10),我们定义变量 i(0 ≤ i ≤ m - 1),根据变量 i 得到路由表如下
| 距离 | 20 | 21 | 22 | … | 2m-1 |
|---|---|---|---|---|---|
| 节点 | node1 | node2 | node3 | … | node_n |
我们把上表中节点与距离的关系生成一张路由表,通过这张表查找节点的时间复杂度为 O(logN),还是很高效的。
一致性哈希新增节点
当有新的节点加入一致性哈希网络的时候,新节点需要与当前网络中的至少一个节点建立联系。此外网络中需要进行如下操作:
- 新加入的节点根据其哈希值与网络中相应位置上的前后两个节点建立联系,这实质上是一个链表的节点插入操作
- 将网络中的数据重新分配,把新加入节点在网络中所对应的数据存储到新加节点上
一致性哈希移除节点
节点的离开分为正常的离开和异常的离开,正常的离开执行的就是节点加入时的逆操作,即重新分配数据与链表节点删除。
节点异常离开有多种解决方案,比如做节点备份。
虚拟节点
考虑到一致性哈希环中节点的状态可能是不完全一样的,例如在实际的网络中有些机器的性能高,可以存储更多的数据并且有更多的吞吐量,有些机器的性能就会比较低,这种现象称为机器的异质性。
我们可以用类似于分片的方式,将一个物理节点拆分为多个虚拟节点,最终我们使用虚拟节点作为一致性哈希环上的节点。高性能的机器可以拥有更多的虚拟节点,存储更多的数据,低性能节点就拥有较少的节点。