HDFS的安装和使用
目录
正如在Hadoop学习笔记中所介绍的那样,我们已经安装好了Java环境并且设置好了JAVA_HOME环境变量,并且下载解压了Hadoop的压缩包。
我们准备三台机器,并且预计将它们的职责设置如下
| 机器 | 角色 |
|---|---|
| 172.19.65.196 | NameNode |
| 172.19.72.108 | DataNode |
| 172.19.72.112 | DataNode |
实现ssh免密访问
在三台机器上面创建hadoop用户并且进入用户的根目录,在三台机器上执行命令创建ssh公私钥
ssh-keygen -t rsa
之后在NameNode上面执行
cat ~/.ssh/id_rsa.pub
获取到master节点的公钥,之后在三台机器(包括master节点自己)上面执行
vi ~/.ssh/authorized_keys
把获取到的master节点的公钥复制进去并保存,随后执行
chmod 644 ~/.ssh/authorized_keys
改变文件的权限信息,之后在NameNode上面执行ssh命令应该就能够实现免密访问了
ssh hadoop@172.19.65.196
ssh hadoop@172.19.72.108
ssh hadoop@172.19.72.112
随后我们可以使用rsync命令将hadoop压缩包传输到另外两个节点上面去,传输完毕解压即可
rsync -azvhP ./hadoop-3.3.2.tar.gz hadoop@172.19.72.108:/home/hadoop
rsync -azvhP ./hadoop-3.3.2.tar.gz hadoop@172.19.72.112:/home/hadoop
修改配置文件
在NameNode上面创建两个文件夹
cd ~
mkdir namenode
mkdir name
在所有DataNode上面创建文件夹
cd ~
mkdir data
1. 修改所有机器的hadoop-env.sh文件
vi ~/hadoop-3.3.2/etc/hadoop/hadoop-env.sh
添加配置如下
JAVA_HOME=$JAVA_HOME
2. 修改所有机器的core-site.xml文件
vi ~/hadoop-3.3.2/etc/hadoop/core-site.xml
添加配置如下
1 | <configuration> |
3. 修改所有机器的hdfs-site.xml文件
vi ~/hadoop-3.3.2/etc/hadoop/hdfs-site.xml
添加配置如下
1 | <configuration> |
4. 修改所有机器的workers文件
vi ~/hadoop-3.3.2/etc/hadoop/workers
修改配置如下
172.19.72.108
172.19.72.112
启动HDFS
在NameNode上执行命令格式化hdfs
./hadoop-3.3.2/bin/hdfs namenode -format
随后在NameNode上启动hdfs
./hadoop-3.3.2/sbin/start-dfs.sh
在NameNode上执行jps能看到有NameNode和SecondaryNameNode进程
[hadoop@lin-65-196 ~]$ jps
30690 SecondaryNameNode
30819 Jps
30462 NameNode
在DataNode上就有DataNode进程
[hadoop@lin-72-108 ~]$ jps
19984 Jps
19909 DataNode
在NameNode上往hdfs写入数据
./hadoop-3.3.2/bin/hadoop fs -mkdir -p /test/input
./hadoop-3.3.2/bin/hadoop fs -put ~/hadoop-3.3.2/etc/hadoop/core-site.xml /test/input
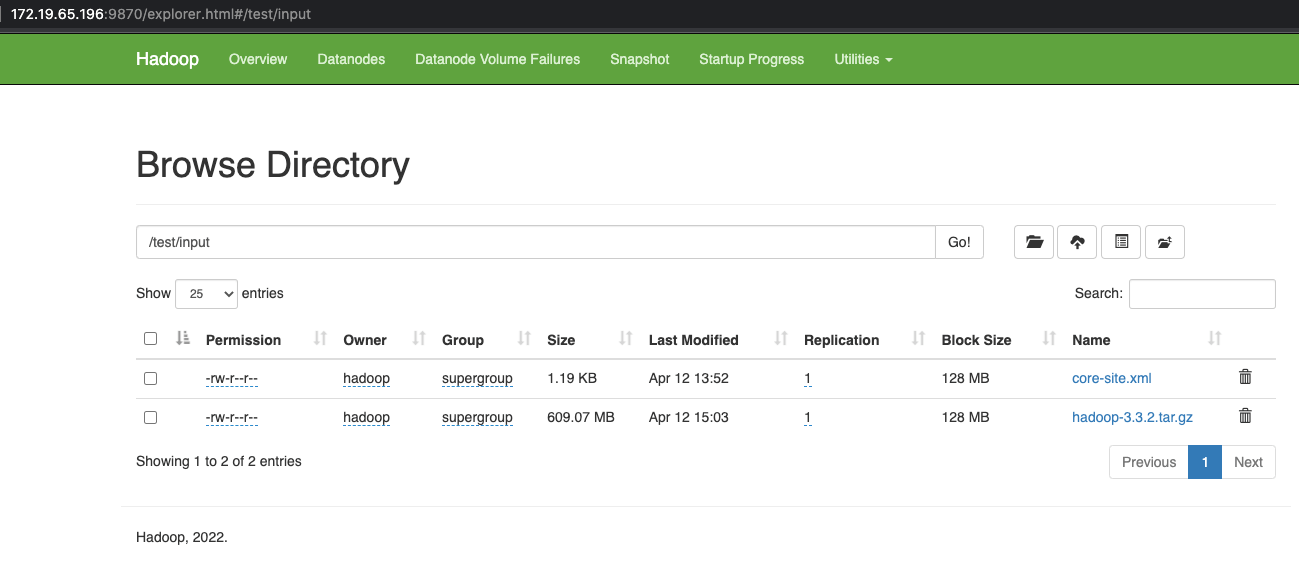
访问http://172.19.65.196:9870/explorer.html#/test/input就可以看到我们创建的文件了
测试完毕可以停止hdfs
./hadoop-3.3.2/sbin/stop-dfs.sh
参考
本文链接: https://www.nosuchfield.com/2021/04/12/Installation-and-use-of-HDFS/
版权声明: 本博客所有文章均采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处!