聊聊 Elasticsearch 中的文本分析
目录
本文使用到的是 Elasticsearch-7.5.2 与 Lucene-8.3.0
Elasticsearch 中的 string 类型存在着两种不同的类型。一种是结构化的数据称为 keyword,elasticsearch 在索引时不会对这类数据做任何的处理;另一种是非结构化的数据称为 text,elasticsearch 在对这类型的数据做索引之前,会先对原始的 string 数据做一定的分析处理,之后得到一些结构化的数据结果,然后针对这些结构化的数据做进一步的处理。
例如一个 field 的类型是 text,则 Elasticsearch 在对这个字段进行索引的时候,会先把这个 field 的值分词为 tokens 之后再保存这些 tokens。而在查询时如果我们使用 match 查询,则 Elasticsearch 会对 match 查询的值进行分词得到 tokens,之后才会使用这些 tokens 进行真正的查询操作。
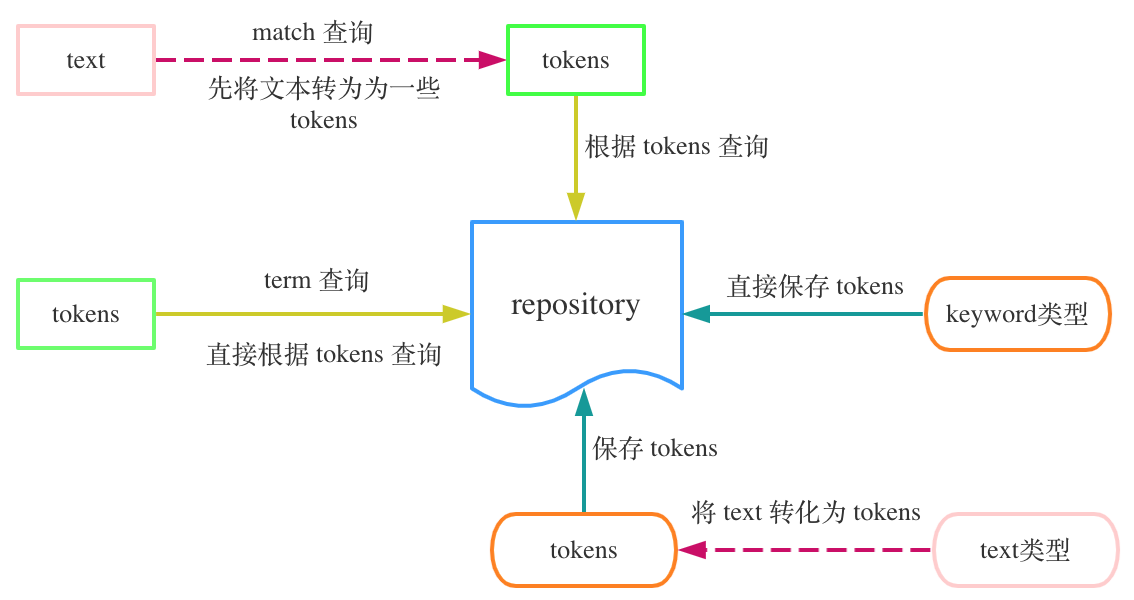
上图显示了 Elasticsearch 中结构化数据与非结构化数据的保存与查询流程,需要注意的是,Elasticsearch 最终只保存结构化的数据,不会保存非结构化的数据。因此我们可以保存一个 text 类型的数据到 ES 中,之后使用 term 方式来进行查询,这也是可以的。
Elasticsearch Text Analysis
从非结构化字符串转化为结构化字符串的过程在 Elasticsearch 中称为 Text analysis,Text analysis 流程又分为如下的几个子流程:
- 使用零个或者多个 Character filters,对原始的文本进行一些处理
- 使用唯一的 Tokenizer,对原始的文本进行分词处理,得到一些 tokens/terms
- 使用零个或者多个 Token filters,对上一步的 tokens 继续进行处理,例如合并同义词等
我们可以使用如下命令在 es 中给一个 text 字段设置指定的 analyzer
PUT my_index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace",
“search_analyzer”: “simple” # 可选,默认是 analyzer 的值
}
}
}
}
以上的 analyzer 为字段在索引时使用,在查询时字段按照如下优先级使用 analyzer 进行分析:
- 查询时手动指定的 analyzer
- 被查询字段的 search_analyzer 属性
- 索引的 default 的 analyzer 的 type
- 被查询字段的 analyzer 属性
es 中包含了很多内置的 analyzer,例如上面的 simple 和 whitespace,这些 analyzer 能够做到开箱即用。此外 es 中还包含了很多内置的 filter、tokenizer 和 char_filter,我们也可以使用这些基础组件构建出一些自定义的 analyzer,如下就是一个例子
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
“type”: “custom”, # 这里设置为 custom 表示自定义一个 analyzer
"tokenizer": "standard",
"char_filter": [
"html_strip"
],
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
}
}
es 的自定义 analyzer 功能给文本处理提供了极大的方便,在内置的 analyzer 无法满足我们的文本分析需求时,我们可以使用内置的 character_filter、tokenizer 和 token_filter 来构建符合我们需要的自定义 analyzer,这已经十分强大了。但是在有的时候,即使是由 character_filter、tokenizer 和 token_filter 自定义的 analyzer 也无法满足我们的文本分析要求,这时候就需要用到 elasticsearch 的 Analysis 插件体系了。
Elasticsearch Plugins
Elasticsearch 包含了很多官方以及社区贡献的 plugin,这些插件都可以在 es 中进行安装或删除:
./bin/elasticsearch-plugin install analysis-smartcn
./bin/elasticsearch-plugin remove analysis-smartcn
# 或者下载了安装包之后手动的安装 plugin
./bin/elasticsearch-plugin install file:///home/elasticsearch/elasticsearch-analysis-ik-7.5.2.zip
在 plugin 中有一类叫做 Analysis Plugin,该类 plugin 可以帮助 es 扩展文本分析的能力。下面我们来详细了解一下如何实现自己的 analysis plugin 和创建新的 analyzer、tokenizer 等等组件,以及如何在 es 中使用这些我们自己创建的插件。
Elasticsearch 的分词器插件本质上使用的是 Lucene 的分词器插件,所以我们需要从两个部分来介绍 Elasticsearch 的分词器插件
- Elasticsearch 如何调用 Lucene 的分词器插件
- Lucene 如何自定义一个分词器插件
Elasticsearch 调用分词器插件
如果我们需要写一个能够让 Elasticsearch 进行调用的插件,首先我们要实现一个继承自 org.elasticsearch.plugins.Plugin 的类,并且该类需要实现 org.elasticsearch.plugins.AnalysisPlugin 接口参考 (一)。你可以重写 AnalysisPlugin 接口的 getAnalyzers 方法,该方法最终会返回一个 org.apache.lucene.analysis.Analyzer 的对象,该对象就是一个实现了自定义分词操作的 Lucene 类型对象;你也可以重写 AnalysisPlugin 接口的 getTokenizers 方法,该方法最终会返回一个 org.apache.lucene.analysis.Tokenizer 的对象,该对象实现了你自定义的分词逻辑。关于这些自定义 Lucene 分词器的创建会在下一节进行详细介绍。AnalysisPlugin接口中还包含了一些其它的方法,更多信息可以参考 该类的源代码。
下面我们看一个实际的例子,首先我们创建 AnalysisQianmiPlugin 类,它继承 Plugin 类且实现了 AnalysisPlugin 接口,它还重写了 AnalysisPlugin 接口的getAnalyzers方法,具体如下
1 | public class AnalysisQianmiPlugin extends Plugin implements AnalysisPlugin { |
上面的类中我们定义了两个 ES 的 Analyzer,它们的名字分别为 qm_standard 和 sub,我们选择 qm_standard 分析器的 provider 即 QianmiStandardAnalyzerProvider参考 (二)来做进一步的了解,QianmiStandardAnalyzerProvider 的实现如下
1 | public class QianmiStandardAnalyzerProvider extends AbstractIndexAnalyzerProvider<Analyzer> { |
QianmiStandardAnalyzerProvider 继承自 Elasticsearch 的 AbstractIndexAnalyzerProvider 类,并且重写了 public Analyzer get() 方法,该方法返回一个 org.apache.lucene.analysis.Analyzer 对象,具体 Analyzer 类的实现会在后一节中做进一步介绍。在 AnalyzerProvider 类的构造方法中我们还传入了 Elasticsearch 的一些属性,包括了
| 属性 | 含义 |
|---|---|
| IndexSettings | Elasticsearch 中索引的信息 |
| Environment | Elasticsearch 的环境属性 |
| AnalyzerName | 当前分析器的名称 |
| Settings | 当前分析器的属性 |
上面传入的这些属性我们可以在 Lucene 的分词过程中根据需要进行使用。
在创建了上面的类并且实现了相应的分词逻辑之后,我们可以对代码进行打包得到一个 jar。之后我们把该 jar 包和一个 ES 插件的 描述文件 放在同一个文件夹中,然后把这个文件夹打包为一个 zip 文件,得到的这个 zip 文件就是一个 ES 的 plugin 了。
Elasticsearch 的描述文件固定为 plugin-descriptor.properties,它一般包含了如下的内容
# 插件的描述信息
description=${project.description}
# 插件的版本号
version=${project.version}
# 插件的名称
name=${elasticsearch.plugin.name}
# 插件的全限定路径,就是之前继承自 Plugin 的那个类的全限定路径
classname=${elasticsearch.plugin.classname}
# 使用的 Java 版本信息
java.version=${elasticsearch.plugin.java.version}
# 插件对应的 Elasticsearch 的版本
elasticsearch.version=${elasticsearch.version}
随后我们可以使用如下命令将该 pulgin 安装到 Elasticsearch 中
./bin/elasticsearch-plugin install file:///Users/derobukal/elasticsearch-analysis-ansj/target/releases/elasticsearch-analysis-qianmi-7.5.2-release.zip
Lucene 自定义分词器插件
在上面 Elasticsearch 调用分词插件的介绍中我们已经知道了 Elasticsearch 最终会需要一个 org.apache.lucene.analysis.Analyzer 的对象来实现真正的分词操作,下面我们就来了解一下我们如何定义一个这样 Lucene 的类。如下就是一个例子,QianmiStandardAnalyzer 继承自 Analyzer 并且重写了其createComponents方法
1 | public class QianmiStandardAnalyzer extends Analyzer { |
方法 createComponents 返回了一个 TokenStream,TokenStream 会协助生成 token。在上面的方法中我们使用到了一个名为QianmiStandardTokenizer的类,这个 tokenizer 实现了最终的分词逻辑。我们也可以看到我们在 Elasticsearch 中所提到的 character_filter、tokenizer 和 token_filter 其实都是 Lucene 中的概念,在这里我们只用到了 tokenizer,其实在createComponents也是可以定义一些 filter 的,因为这里没有用到就不介绍了。
QianmiStandardTokenizer 继承自org.apache.lucene.analysis.Tokenizer类,该类需要重写 Tokenizer 类的public boolean incrementToken()和public void reset()方法。除此之外,Tokenizer 还需要用到一些 attribute 来保存分词的信息。
attribute 属性
attribute 属性用于保存我们分词的一些结果信息,例如分词本身、分词的类型、分词的位置、分词的长度,等等。如下我们定义了三个属性
1 | // 分词的属性 |
当我们得到分词之后,只需要把这些信息保存到 attribute 中,后续的流程可以从这些 attribute 取出相应的数据。
incrementToken() 方法
每一次该方法执行就会得到一个分词结果,如果该方法返回 true 则表示还存在分词可以继续获取,返回 false 则表示分词已经获取完毕,我们只需要在该方法中把得到的分词信息保存我们上面所说的 attribute 中,Lucene 会从属性中获取到这些分词的结果信息。
需要注意的是,在执行这个方法时需要先执行clearAttributes()方法来清除 attribute 属性的中信息,目的是为了防止上一次的分词信息对这一次的分词结果产生影响。下面我们看一个该方法的例子
1 | public boolean incrementToken() throws IOException { |
reset() 方法
该方法在每段文本分词前都会调用,目的是恢复一些环境属性,防止多个文本的分词互相影响。注意在重写该方法时需要调用super.reset()以协助恢复一些 Lucene 本身的环境属性。假设我们需要在每次文本分析前恢复文本读取的 offset 变量
1 | public void reset() throws IOException { |
在 Lucene 分词插件这一小节我们知道了如何定义 Analyzer、Tokenizer 以及如何在 Tokenizer 中实现分词逻辑。
参考
(一)
除 AnalysisPlugin 之外,如果你想实现一些其它类型的插件,那么只需要创建一个继承自Plugin的类并且实现指定的插件接口即可,Elasticsearch 所有的 Plugin Interface 在类Plugin的文档中都有 详细的介绍。总结起来在 Elasticsearch 中创建插件的简单流程就是创建一个继承自Plugin类并且实现了指定类型插件(例如 AnalysisPlugin)的接口的类。
(二)
这里的QianmiStandardAnalyzerProvider::new是一个 lambda 表达式,其转化过程如下:
- 这里需要一个实现了接口 AnalysisModule.AnalysisProvider 的类的对象;
- AnalysisModule.AnalysisProvider 接口有一个 get 方法为虚拟方法,实现该接口的类需要实现该方法;
- 我们并不需要真的去实现一个类并且让该类实现这个 get 方法,而是可以使用匿名内部类的方式实现;
- (如果不使用匿名内部类)
- 实现一个类,让该类实现 AnalysisModule.AnalysisProvider 接口;
- 该类也需要实现 get 方法,get 方法的逻辑还是一样的;
- 之后在这里创建一个该类的对象即可;
- 如果使用匿名内部类,则只需要实现 get 方法即可:
1
2
3
4
5
6new AnalysisModule.AnalysisProvider<AnalyzerProvider<? extends Analyzer>>() {
public AnalyzerProvider<? extends Analyzer> get(IndexSettings indexSettings, Environment environment, String name, Settings settings) throws IOException {
return new QianmiSubAnalyzerProvider(indexSettings, environment, name, settings);
}
} - 由于该接口只需要实现一个 get 方法,所以可以使用 lambda 表达式对如上的代码优化如下:
1
2
3(indexSettings, env, name, settings) -> {
return new QianmiSubAnalyzerProvider(indexSettings, env, name, settings);
} - 由于该方法的方法体只有一行,所以可以把上面的表达式进一步的优化为如下的 lambda 表达式:
1
(indexSettings, env, name, settings) -> new QianmiSubAnalyzerProvider(indexSettings, env, name, settings)
- 由于 get 方法的参数和后面创建对象的参数一致,所以可以使用 lambda 表达式进行进一步的优化:
1
QianmiSubAnalyzerProvider::new
(三)
如何在 Lucene 中调用 Analyzer 进行分词呢?在 Lucene 的 官网中有如下文档

具体的使用方式如下
1 | String content = "如何在Lucene中调用Analyzer进行分词呢?在Lucene的官网中有如下文档"; |
(四)
如何在 Elasticseach 中使用指定的分词器呢?在插件安装完毕之后,我们重启 Elasticsearch 节点。之后在创建索引时我们可以指定字段的类型
PUT http://localhost:9200/test
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "qm_standard"
},
"prefix": {
"type": "sub",
"section": "0:3;0:5"
},
"postfix": {
"type": "sub",
"section": "-6:-1;-4:-1"
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "qm_standard"
}
}
}
}
如上我们可以使用默认的分析器如 qm_standard,也可以根据已存在的分析器定义一些新的分析器,例如 prefix 分析器就来自于 sub 分析器。其中自定义分析器的配置信息会传到上面提到的 AnalyzerProvider 类的 Settings 变量中,我们可以使用这些配置信息来定义一些新的分词逻辑。
下面是一个使用指定分析器在 Elasticsearch 中进行分词测试的例子
POST http://localhost:9200/test/_analyze
{
"analyzer": "postfix",
"text": "TCC20040112442814525679"
}
{
"tokens": [
{
"token": "525679",
"start_offset": 17,
"end_offset": 22,
"type": "word",
"position": 0
},
{
"token": "5679",
"start_offset": 19,
"end_offset": 22,
"type": "word",
"position": 1
}
]
}
相关文档
Elasticsearch 的文本分析
ELasticsearch 的插件体系
使用 Java 实现 Elasticsearch 自定义插件的参考文档
Elasticsearch 源码中关于插件部分的示例
自定义 Lucene 的分词器 Analyzer
Package org.apache.lucene.analysis
Apache LuceneTM 8.3.0 Documentation
https://github.com/RitterHou/elasticsearch-analysis