Lucene学习笔记
Lucene是由Doug Cutting大神开发的,这哥们同时还创立了Nutch和Hadoop,他和QEMU、FFmpeg、tinycc、QuickJS的发明者Fabrice Bellard一样多产且开发的东西都十分牛逼。
Lucene是一个Java开发的搜索引擎,其全文检索基于Inverted Index实现。此文章所使用的代码都可以在RitterHou/test_lucene中找到。
基础使用
首先我们对数据进行索引操作,这里我们选择了把数据存储在RAM中,但是要知道Lucene也支持把数据存储在磁盘上。
1 | private void index () { |
上面的代码包含了
- 创建内存Dir
- 创建IKAnalyzer分词器,这是一个中文分词器;把该分词器放到config对象中
- 创建IndexWriter对象
- 将数据创建为一条条的Document(文档)并进行存储
上一步操作中数据已经被保存成功,下面进行数据检索的操作。
1 | Directory directory = new RAMDirectory(); |
- 和IndexWriter使用同一个Dir
- 创建查询语句,我们这里是根据
title字段查询,因为这是一个TextField所以用于查询的字符串也需要先使用IKAnalyzer进行分词 - 根据查询语句查询出
hits - 根据
hits中的docId取回数据
基础查询的完整代码位于SimpleTest.java
NRT查询
我们知道Lucene存储引擎使用的是LSM Tree形式,关于LSM Tree可以参考我之前的文章Log structured merge tree,简而言之Lucene会把数据写到一个个的段(Segment)中。所谓NRT查询即Near Real Time查询,这意味着我们写到Lucene的数据是不能够被立即查询到的,原因如下
Segment在被flush或commit之前,数据保存在内存中,是不可被搜索的,这也就是为什么Lucene被称为提供近实时而非实时查询的原因。读了它的代码后,发现它并不是不能实现数据写入即可查,只是实现起来比较复杂。原因是Lucene中数据搜索依赖构建的索引(例如倒排依赖Term Dictionary),Lucene中对数据索引的构建会在Segment flush时,而非实时构建,目的是为了构建最高效索引。当然它可引入另外一套索引机制,在数据实时写入时即构建,但这套索引实现会与当前Segment内索引不同,需要引入额外的写入时索引以及另外一套查询机制,有一定复杂度。 —— Lucene解析 - 基本概念
上面解释了Lucene不能实现实时查询的原因,下面我们看一看如何能实现NRT查询
首先还是创建配置等这一套代码
1 | Analyzer analyzer = new IKAnalyzer(); |
随后是NRT的配置以及开启NRT的定时刷新线程
1 | // NRT查询的相关配置 |
其中最重要的就是ControlledRealTimeReopenThread类的1.0和0.1这两个参数
- targetMaxStaleSec: reader的最大open间隔
- targetMinStaleSec: reader的最小可open间隔
有了以上这些设置,我们就能实现不重新打开reader也可以读到最新的数据了,当然读取的数据对应写入的数据并不是实时的。
完整代码位于NRTTest.java
相关度打分
一般的数据库的查询中,某一条数据针对指定查询条件只存在符合要求或者不符合要求这两种情况;而搜索引擎则还需要提供某条数据与查询条件有多大程度相似的这种情况,这种比较相似度的需求就是通过相似度打分的计算来实现的。在搜索引擎进行查询的同时也会计算指定文档与查询条件的相似度得分,得分高的一般来说就需要优先展示。
Lucene内部包含了多种相似度算法,其中最经典的就是TF/IDF算法,Lucene的TF/IDF计算实现位于 org.apache.lucene.search.similarities.TFIDFSimilarity 类中。除了TF和IDF,Lucene在该类中计算得分时还会使用到一些其它的参数
| 计算因子 | 介绍 |
|---|---|
| coord | 指定文档中命中的查询关键词个数 ÷ 所有的查询关键词个数 |
| TF | term在指定文档中出现的次数,次数越多得分越高 |
| IDF | term在全部文档中出现的次数,次数越多得分越低 |
| boost | 一个影响因子,供用户在查询时修改以影响最终得分 |
| queryNorm | 常数 |
| norms | 文档的长度,长度越短权重越高 |
coord实现
1 | /** Implemented as <code>overlap / maxOverlap</code>. */ |
TF的实现
1 | /** Implemented as <code>sqrt(freq)</code>. */ |
IDF的实现
1 | /** Implemented as <code>log(numDocs/(docFreq+1)) + 1</code>. */ |
计算最终得分的公式如下(公式来自Lucene官方文档)

提升搜索速度
我们知道Lucene使用反向索引存储数据,例如针对如下数据
| id | 标题 | isbn |
|---|---|---|
| 1 | 游戏编程算法与技巧 | 9787121276453 |
| 2 | 计算机程序的构造和解释(原书第2版) : 原书第2版 | 9787111135104 |
| 3 | 编码 : 隐匿在计算机软硬件背后的语言 | 9787121106101 |
| 4 | 计算机网络(第5版) | 9787302274629 |
| 5 | Python网络编程攻略 | 9787115372697 |
| 6 | UNIX网络编程 | 9787302119746 |
| 7 | 算法导论(原书第3版) | 9787111407010 |
针对上面的数据我们可以构建的部分反向索引结构如下
标题的反向索引:
| 关键词 | doc_ids |
|---|---|
| 算法 | [1, 7] |
| 编程 | [1, 5, 6] |
| 计算机 | [2, 3, 4] |
isbn的反向索引:
| 关键词 | doc_ids |
|---|---|
| 9787121106101 | 3 |
| 9787115372697 | 5 |
根据上表我们知道Lucene需要构造一个 关键词 -> doc_id 之前的关系映射,如果让我自己实现一个映射关系那我很可能会选择使用哈希表,即关键词使用哈希表的方式进行查找。Lucene选择了使用一个类似于trie树叫做FST(Finite State Transducer)的数据结构来保存关键词,虽然FST在写入和查找速度上都不及哈希表,但是它在前缀查找等方式上却有着巨大的优势,此外FST十分的节省空间,这使得我们可以把FST全部放在内存中以提高数据操作速度。关于FST可以参考这篇文章。
Lucene的数据存储架构如下
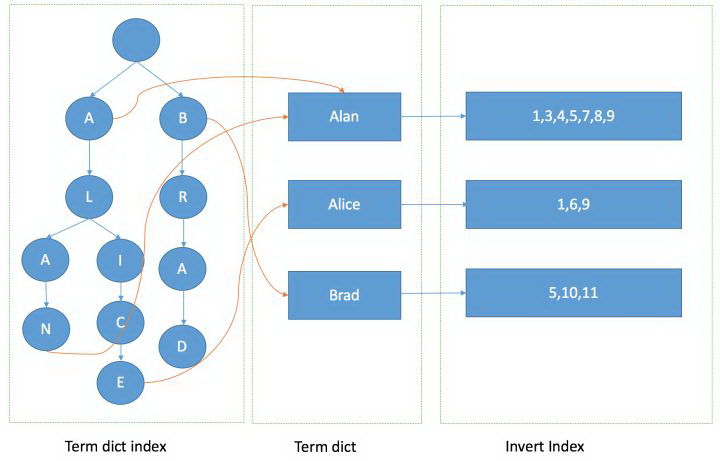
上面我们介绍的FST其实是Term dict index这一部分,通过Term dict index我们可以找到Term dict中的相应term,例如上面我们提到的 计算机 或者 9787121106101 等等。找到了相应的term之后我们可以继续根据term找到相应的Inverted Index,Inverted Index使用SkipList保存,SkipList可以让多个term的查询结果合并速度更快。顺便提一下,Elasticsearch会对filter类型的查询结果使用bitset进行缓存,如果下次查询缓存命中则可以直接通过bitset的缓存进行结果合并,速度更快。
生成正向索引
我们上面提到的都是数据检索阶段的工作,也看到了Inverted Index在数据检索上十分优秀,但是当我们已经取回了数据需要对数据做进一步的排序或聚合时,反向索引就显得力不从心了。Lucene需要把取回的数据通过计算再生成一份正向索引,之后使用正向索引实现排序或聚合等操作,生成正向索引十分耗费资源,因此Lucene4之后对这些生成的正向索引做了缓存即fieldcache,这样这些正向索引的结果就会被缓存在内存中,fieldcache的命中可以大大提高数据排序或聚合的速度。
fieldcache对内存是一个很大的挑战,如果缓存数据过多会导致内存占用过高。新版的Lucene中引入了DocValues概念,Lucene会在数据索引阶段就生成一份列式存储的正向索引,即DocValues。DocValues因为是在索引阶段生成的,又被保存在磁盘上,所以避免了fieldcache会产生的一些问题。当然,DocValues会增加磁盘空间的使用,所以Lucene允许我们只针对某些需要排序或聚合的字段使用DocValues,这样就节省了部分的磁盘空间。
参考
Welcome to Lucene Tutorial.com - Lucene Tutorial.com
Lucene 近实时搜索 | IT草根
Lucene解析 - 基本概念
Lucene原理与代码分析 - 随笔分类
lucene 的评分机制
Lucene 查询原理及解析
Lucene中的文本相似度算法
Okapi BM25, TF-IDF, 以及 ElasticSearch/Lucene 搜索结果的分数
elasticsearch-full
Lucene查询原理
ElasticSearch 查询的秘密
Elasticsearch Modules