多路复用、非阻塞、线程与协程
线程与阻塞
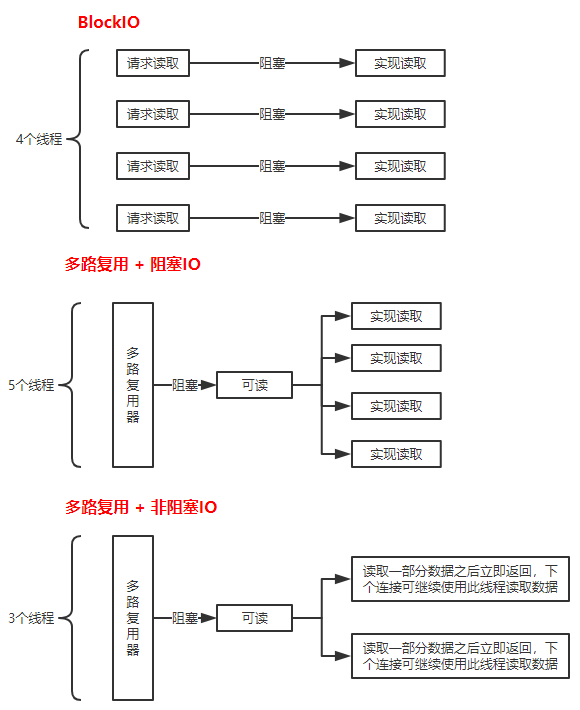
在传统的 blockIO 中,一个 TCP 连接的可读事件与用户的实际读取操作是糅合在一起的。用户想要读取数据只需要调用 read 系统调用,之后当前线程会阻塞在这里直到当前连接的读缓冲区有数据可读,此时操作系统会调度让此线程退出阻塞状态继续执行,在用户态我们就可以实现读取数据的操作了。
此时的读取操作都是阻塞的,不过因为用户直接用一个线程来实现一个连接的读写,当前线程的阻塞并不会对其它的连接产生影响,所以阻塞也无所谓。
后来因为 C10k 问题,也就是如何让一个操作系统能同时维护 10k 个连接的问题的提出,传统的 blockIO 模型已经不能符合人们此时的需求。因为在传统的 IO 模型中,TCP 连接的可读可写事件以及读写操作本身都被实现在 READ 和 WRITE 系统调用中,而读写事件本身会阻塞当前线程,这也就导致了我们必须要给每一个读写操作分配一个单独的线程。
因为传统 IO 需要一个连接对应着一个线程,所以当连接数过多时线程数也很多,现代操作系统在线程过多时运行效率会明显降低,这主要是因为两个原因
- 操作系统需要为每一个线程存储一些 meta 信息(包括线程的当前上下文状态等等),当线程数过多时,会对内存造成一定的压力。
- 操作系统的线程切换操作是十分耗费系统资源的,当线程数过多时,线程切换的频率大大增加,线程切换次数变多会导致整个系统的吞吐量降低,因而会影响用户程序的执行效率。
现代操作系统使用多路复用和非阻塞来解决 C10K 问题,它们的核心在于细化了对连接的管理方式。以前我们管理连接只能使用 READ 和 WRITE,然后无脑开个线程,让操作系统来帮助我们管理连接的可读可写事件。为了解决这些问题,我们开始需要自己管理连接的读写事件。
首先我们把连接的操作进行拆分,不再像以前那样 READ 和 WRITE 一把梭,而是把可读可写和读写操作本身进行拆分。我们之前说过,我们之所以要给每一个连接创建一个线程,是为了能让操作系统帮助我们管理每一个连接的读写事件。
多路复用
我们把一个连接的可读可写事件剥离出来,使用单独的线程来对其进行管理,这里的关键点在于此线程不仅可以管理一个线程的可读可写事件,事实上这个线程中我们可以管理多个连接的可读可写事件,这个线程中实现的操作就叫多路复用,多路复用需要操作系统提供相应的 syscall 才可以使用。
有了多路复用器,连接与线程之间的紧密联系被拆开。不再需要太多的线程,我们可以在仅一个线程中就维护着数百万个连接的读写事件,C10k 问题被解决。
非阻塞
多路复用解决的是维护大量 TCP 连接的状态以及它们的可读可写事件的问题,这是我们在连接的可读可写事件上进行的优化,接下来我们需要对连接数据的读写操作本身进行优化。
一般来说,在从多路复用器得到了一个连接可读或者可写的讯息之后,我们就需要对这个连接进行读写操作了。因为多路复用器所在的线程可能会阻塞,所以我们一般会把这些连接的读写操作放到新的线程中。因为读写操作本身也可能导致线程阻塞(例如读取数据的数量还不满足要求),所以此时我们仍然需要为每一个连接的读写操作开辟新的线程(也可以使用线程池),这在读写连接较少的情况下没什么问题,但是在有大量连接都需要进行读写操作时仍然会产生大量的线程,降低系统吞吐量。
解决办法是使用非阻塞 IO,即一旦当前连接读缓冲区中的数据已被读完或当前连接的写缓冲区中的数据已满,则 READ 或 WRITE 系统调用立即返回,而不是阻塞住当前线程。有了非阻塞 IO,我们就可以在一个线程中进行多个连接的读写操作而不用担心某一个连接会导致当前线程阻塞,这样我们就能降低读写操作所需要的线程的数量了。
| 传统 IO | 多路复用 | 非阻塞 |
|---|---|---|
| 读写事件被绑定在读写操作上,读写操作本身是阻塞的 | 把读写事件剥离出读写操作本身,单个线程可以管理数百万个连接的读写事件,读写操作本身还是阻塞的 | 读写操作本身是非阻塞的,可以在少量线程中实现大量连接的读写操作 |
这三种类型的 IO 模型的使用情况如下图:
协程
协程是用户态层面的代码执行管理单元,可以类比操作系统的线程。
| 类型 | 线程 | 协程 |
|---|---|---|
| 被调度时 meta 数据的存储区域 | 内核态内存空间 | 用户态内存空间 |
| 切换操作 | 需要调用操作系统内核提供的 syscall | 简单的现场保存和恢复即可 |
| 调度机制 | 现代操作系统都是抢占式的,由内核实现 | 依赖当前协程主动让出(yield)CPU 资源 |
由于多路复用与非阻塞的使用,导致单个连接的状态管理不再像 BlockIO 时那样的简单,而且因为线程不会阻塞在读写操作、尤其是读操作上,所以此时我们一般使用回调函数的方式来实现读操作。简单来说就是在读取时,如果已经读取的数据还不满足需求,程序就暂时把这些数据读取并保存在用户态的内存中,待数据读取满足要求之后就调用回调函数,通过异步的方式把数据交给相应的处理函数。
异步的问题在于不便于程序员的理解,人类更加习惯于同步的操作行为,异步的操作总是会显得晦涩而又难以理解,这会提升代码的复杂度。
我们可以使用协程对多路复用和非阻塞进行改造来实现同步的 IO 操作。首先我们在协程中调用我们自己实现的方法 READ0,该方法为阻塞方法,此时该协程被阻塞。在语言内部我们使用多路复用和非阻塞来管理连接和数据,一旦数据满足了要求,我们再次调度到该协程,此时 READ0 方法返回,在用户看来整个 READ0 方法就是同步阻塞的,非常易于程序员的使用。
此外,由于协程的数据都存储在用户态的内存空间且不需要通过 syscall 即可以调度,所以协程的调度相较于线程是非常轻量级的,事实上在 go 语言中我们可以开数十万个协程而不会有性能问题,而同样的机器上运行数千个线程就已经很吃力了。
协程和线程不存在相互替代的关系,它们都是对一个指定的逻辑流的抽象,它们之间是互补的关系。协程和线程的发展历史大致如下:
- 早期一台计算机上面只能执行一个程序
- 一台机器上只执行一个程序太浪费 CPU 资源了,我们可以写一个控制程序,当某个程序执行 IO 时就让出 CPU 资源交给另一个程序执行,这就是协程的思想
- 在多任务操作系统中,为了避免某个程序一直霸占 CPU 资源,抢占式的操作系统被发明,由操作系统内核对 CPU 的资源进行管理和分配(事实上不仅仅是 CPU,现代操作系统实现了对计算机所有的硬件资源的高效的管理)
- 多核 CPU 被发明,我们可以直接在操作系统层面支持多核,面向程序员的线程模型无需改变
- 线程的切换需要内核的帮助,比较耗费系统资源。为了避免大量的使用线程,我们可以在单个进程中模拟早期的调度程序的行为,从而实现多个逻辑流的执行,这就是协程
在操作系统层面,线程实现了抢占式多任务处理以及对多核 CPU 的支持;在用户层面,协程提供了统一的逻辑流的抽象,并向上提供编程模型。协程和线程之间是互补的关系,它们本质上都只是对一些的状态的维护。
参考
https://tiancaiamao.gitbooks.io/go-internals/content/zh/08.1.html