程序的编译、链接、装载与运行
目录
在Linux操作系统中,一段C程序从被写下到最终被CPU执行,要经过一段漫长而又复杂的过程。下图展示了这个过程
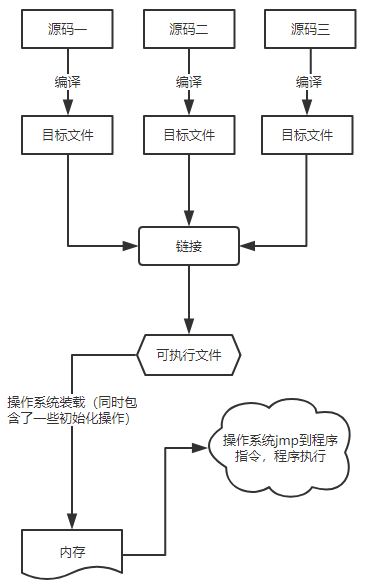
目录
1. 编译
编译就是把程序员所写的高级语言代码转化为对应的目标文件的过程。一般来说高级语言的编译要经过预处理、编译和汇编这几个过程。
预处理
预编译过程对源代码做了如下的操作
- 删除所有的注释信息
- 删除所有的 #define 并展开所有宏定义
- 插入所有 #include 文件注1的内容到源文件中的对应位置,include过程是递归执行的
- …
gcc可以使用如下命令对C语言进行预编译并且把预编译的结果输出到hello.i文件中
gcc -E hello.c -o hello.i
编译
编译就是对预处理之后的文件进行词法分析、语法分析、语义分析并优化后生成相应的汇编文件。我们使用如下命令来编译预处理之后的文件
gcc -S hello.i -o hello.s
或者我们也可以把预处理和编译合为一步
gcc -S hello.c -o hello.s
汇编
汇编的目的是把汇编代码转化为机器指令,因为几乎每一条汇编指令都对应着一条机器指令,所以汇编的过程相对而言非常的简单。我们可以使用如下命令实现汇编
gcc -c hello.s -o hello.o
或者我们也可以直接把源代码文件编译为目标文件
gcc -c hello.c -o hello.o
汇编操作所生成的文件叫做目标文件(Object File),目标文件的结构与可执行文件是一致的,它们之间只存在着一些细微的差异。目标文件是无法被执行的,它还需要经过链接这一步操作,目标文件被链接之后才可以产生可执行文件。
下面我们了解一下目标文件的格式以及链接这一步具体做了哪些工作。
2. 目标文件的格式
Linux下的目标文件格式叫做ELF(Executable Linkable Format),ELF的格式如下图所示: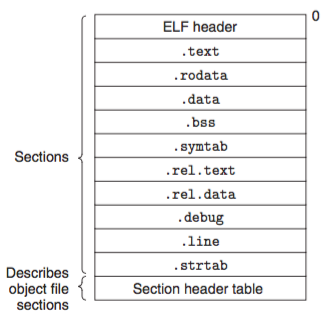
ELF header是ELF文件中最重要的一部分,header中保存了如下的内容
- ELF的magic number
- 文件机器字节长度
- ELF版本
- 操作系统平台
- 硬件平台
- 程序的入口地址
- 段表的位置和长度
- 段的数量
- …
从header中我们可以得到很多有用的信息,其中的一个尤其重要,那就是段表的位置和长度,通过这一信息我们可以从ELF文件中获取到段表(Section Hedaer Table),在ELF文件中段表的重要性仅次于header。
段表保存了ELF文件中所有的段的基本属性,包括每个段的段名、段在ELF文件中的偏移、段的长度以及段的读写权限等等,段表决定了整个ELF文件的结构。
既然段表决定了所有的段的属性,那么ELF文件中的段究竟是个什么东西呢?其实段只是对ELF文件内的不同类型的数据的一种分类。例如,我们把所有的代码(指令)放到一个段中,并且给这个段起名.text;把所有的已经初始化的数据放在.data段;把所有的未初始化的数据放在.bss段;把所有的只读数据放在.rodata段,等等。
至于为什么要把数据(指令在ELF文件中也算是一种数据,它是ELF文件的数据之一)分为不同的类型,除了方便进行区分之外,还有以下几个原因
- 便于给段设置读写权限,有些段只需要设置只读权限即可
- 方便CPU缓存的生效
- 有利于节省内存,例如程序有多个副本情况下,此时只需要一份代码段即可
既然分段有着诸多的好处,那么接下来我们就近距离的看一看ELF文件中的段信息。有如下的示例文件 hello.c
1 | int printf(const char *format, ...); |
使用如下命令把源代码编译成目标文件
gcc -c hello.c -o hello.o
接下来我们可以使用objdump命令查看ELF文件的内部结构,-h 表示显示ELF文件的头部信息
objdump -h hello.o
得到结果如下
hello.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000055 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000008 0000000000000000 0000000000000000 00000098 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000004 0000000000000000 0000000000000000 000000a0 2**2
ALLOC
3 .rodata 00000004 0000000000000000 0000000000000000 000000a0 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .comment 00000036 0000000000000000 0000000000000000 000000a4 2**0
CONTENTS, READONLY
5 .note.GNU-stack 00000000 0000000000000000 0000000000000000 000000da 2**0
CONTENTS, READONLY
6 .eh_frame 00000058 0000000000000000 0000000000000000 000000e0 2**3
CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATA
可以看到上面的结果中显示了7个段,每个段都有一些属性信息,下面我们了解一下这些属性的含义
- Size:段的大小
- VMA:段的虚拟地址,因为目标文件尚未执行链接操作,所以虚拟地址为0
- LMA:段被加载的地址,同上原因为0
- File off:段在ELF文件中的偏移地址
- CONTENTS:表示此段存在于ELF文件中
- …
我们重点关注.text、.data、.bss和.rodata这几个段:
- .text 段保存了程序中的所有指令信息,objdump的
-s参数表示将段的内容以十六进制的方式打印出来,而-d参数则会对所有包含指令的段进行反汇编,因此使用如下命令就可以获取代码段的详细信息
objdump -s -d hello.o - .data 段保存已初始化的全局变量和局部静态变量
- .bass 段保存未初始化的全局变量和局部静态变量注3
- .rodata 段保存只读数据,例如字符串常量、被const修饰的变量
ELF还包含了很多其它类型的段,感兴趣的话可以查阅相关资料做进一步的了解。
3. (静态)链接
因为现在机器的内存和磁盘空间已经足够大,而动态链接对于内存和磁盘的节省十分有限,所以我们已经可以忽略动态链接带来的在节省使用空间上的优势。相反因为没有了动态链接库的依赖,不需要考虑动态链接库的不同的版本,静态链接的文件可以做到链接即可执行,减少了运维和部署上的复杂度,是非常的方便的,在有些新发明的语言(例如golang)中链接过程默认已经开始使用静态链接。
静态链接过程分为两步
- 扫描所有的目标文件,获取它们的每个段的长度、位置和属性,并将每个目标文件中的符号表的符号定义和符号引用收集起来放在一个全局符号表中,建立起可执行文件到目标文件的段映射关系
- 读取目标文件中的段数据,并且解析符号表信息,根据符号表信息进行重定位、调整代码中的地址等操作
我们有如下的a.c和b.c两个源文件
1 | // a.c |
1 | // b.c |
编译源代码得到目标文件a.o和b.o
gcc -c a.c b.c -zexecstack -fno-stack-protector -g
链接a.o和b.o目标文件得到可执行文件
ld a.o b.o -e main -o ab
在ELF文件中有两个叫做重定位表和符号表的段我们之前没有介绍,它们对于链接过程起着及其重要的作用,接下来我们详细了解一下这两个段
重定位表
可以简单的认为是编译器把所有需要被重定位的数据存放在重定位表中,这样链接器就能够知道该目标文件中哪些数据是需要被重定位的。
我们可以使用 objdump -r a.o 来获取重定位表的信息
...
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
0000000000000014 R_X86_64_32 shared
0000000000000021 R_X86_64_PC32 swap-0x0000000000000004
...
我们也可以使用 readelf -S a.o 命令来详细的了解一个ELF文件
...
[ 1] .text PROGBITS 0000000000000000 00000040
000000000000002c 0000000000000000 AX 0 0 1
[ 2] .rela.text RELA 0000000000000000 00000430
0000000000000030 0000000000000018 I 18 1 8
...
其中以.rela开头的就是重定位段,上面的.rela.text就存放了需要被重定位的指令的信息,同样的如果是需要被重定位的数据则段名应该叫做.rela.data。
上面的操作都是针对目标文件a.o进行的,我们对目标文件b.o执行以上命令可以发现其既不存在数据段的重定位表,也不存在代码段的重定位表。这是因为b.c中的变量shared和函数swap都已经明确的知道了其地址,所以不需要重定位。
而a.c中则不一样,因为在a.c中变量shared和函数swap都没有定义在当前的文件中,因此编译后产生的目标文件中不存在它们的地址信息,所以编译器需要把它们放在重定位表中,等到链接时再到其它目标文件中找到对应的符号信息之后对其进行重定位。
符号表(.symtab)
目标文件中的某些部分是需要在链接的时候被使用到的“粘合剂”,这些部分我们可以把其称之为“符号”,符号就保存在符号表中。符号表中保存的符号很多,其中最重要的就是定义在本目标文件中的可以被其它目标文件引用的符号和在本目标文件中引用的全局符号,这两个符号呈现互补的关系。
使用命令 readelf -s 可以查看符号表的内容
$ readelf -s a.o
...
8: 0000000000000000 79 FUNC GLOBAL DEFAULT 1 main
9: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND shared
10: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND swap
...
$ readelf -s b.o
...
8: 0000000000000000 4 OBJECT GLOBAL DEFAULT 2 shared
9: 0000000000000000 75 FUNC GLOBAL DEFAULT 1 swap
...
$ readelf -s ab
...
10: 0000000000000000 0 FILE LOCAL DEFAULT ABS a.c
11: 0000000000000000 0 FILE LOCAL DEFAULT ABS b.c
12: 0000000000400114 45 FUNC GLOBAL DEFAULT 1 swap
13: 00000000006001a0 4 OBJECT GLOBAL DEFAULT 3 shared
14: 00000000006001a4 0 NOTYPE GLOBAL DEFAULT 3 __bss_start
15: 00000000004000e8 44 FUNC GLOBAL DEFAULT 1 main
16: 00000000006001a4 0 NOTYPE GLOBAL DEFAULT 3 _edata
17: 00000000006001a8 0 NOTYPE GLOBAL DEFAULT 3 _end
...
- 第一列是符号表数组中的坐标
- 第二列是符号值
- 第三列是size
- 第四列是符号类型
- 第五列是绑定信息
- 最后一列是符号的名称
命令 nm 也可实现对符号的查看操作
$ nm a.o
U __stack_chk_fail
0000000000000000 T main
U shared
U swap
$ nm b.o
0000000000000000 D shared
0000000000000000 T swap
$ nm ab
00000000006001a4 D __bss_start
00000000006001a4 D _edata
00000000006001a8 D _end
00000000004000e8 T main
00000000006001a0 D shared
0000000000400114 T swap
其中 D 代表该符号是已经初始化的变量,T 表示该符号是指令,U 代表该符号尚未定义。
从上面的结果我们可以看到,链接过程确实是对目标文件的符号做了“粘合”操作。
问:重定位表和符号表之间是什么关系?
答:它们之间是相互合作的关系,链接器首先要根据重定位表找到该目标文件中需要被重定位的符号,之后再根据符号表去其它的目标文件中找到可以相匹配的符号,最后对本目标文件中的符号进行重定位。
从上面的过程中我们可以看到链接器最终需要完成的工作有三个
- 合并不同目标文件中的同类型的段
- 对于目标文件中的符号引用,在其它的目标文件中找到可以引用的符号
- 对目标文件中的变量地址进行重定位
静态库的链接
操作系统一般都附带有一些库文件,Linux最有名的就是libc静态库,其一般位于 /usr/lib/libc.a,libc.a其实是个压缩文件,里面包含了printf.o,scanf.o,malloc.o,read.o等等的库文件。当使用到标准库中的内容时,链接器会对用户目标文件和标准库进行链接,得到最终的可执行文件。
链接过程的控制
链接默认情况下生成的是一个ELF文件,这在Linux操作系统上是符合我们的要求的。但是我们有的时候想要其它的目标文件格式,甚至我们有时候想自己写操作系统内核,此时ELF文件的格式就显然不能满足我们的要求了。事实上我们可以通过一些命令行参数或者直接使用配置文件的方式来控制链接的过程以及链接产生的结果,详细内容可以参考命令ld的相关文档,这里不再做介绍。
4. 装载
在上一节我们已经通过链接得到了可执行文件,在可执行文件中包含了很多的段(section),但是一旦这些段被加载到内存中之后,我们就不在乎他到底是什么类型的数据,而只在乎这份数据在内存中的读写权限。所以可执行文件被加载到内存中的数据可以分为两类:可读不可写和可读可写。
由于现代操作系统均采用分页的方式来管理内存,所以操作系统只需要读取可执行文件的文件头,之后建立起可执行文件到虚拟内存注5的映射关系,而不需要真正的将程序载入内存。在程序的运行过程中,CPU发现有些内存页在物理内存中并不存在并因此触发缺页异常,此时CPU将控制权限转交给操作系统的异常处理函数,操作系统负责将此内存页的数据从磁盘上读取到物理内存中。数据读取完毕之后,操作系统让CPU jmp到触发了缺页异常的那条指令处继续执行,此时指令执行就不会再有缺页异常了。
忽略物理内存地址以及缺页异常的影响,一旦操作系统创建进程(fork)并载入了可执行文件(exec),那么虚拟内存的分布应该如下图所示
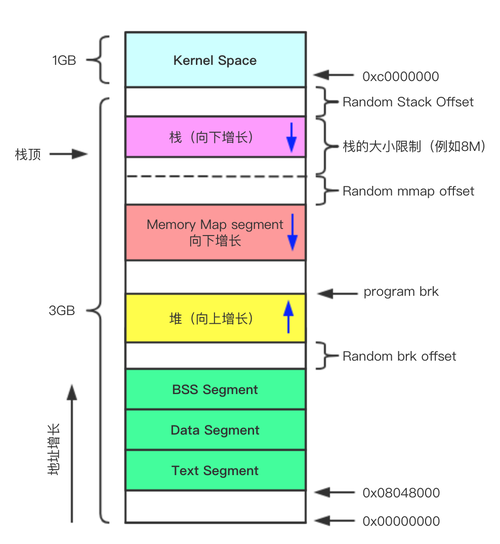
可以看到在ELF文件中的多个section在内存中被合并为3个segment
| Segment name | Data type | |
|---|---|---|
| 1 | BSS segment | 保存未初始化的数据 |
| 2 | Data segment | 保存已经初始化的数据 |
| 3 | Text segment | 保存程序的指令 |
上面的图片中除了三个保存了ELF文件的数据的segment之外,还有如下的几个部分
| 名称 | 描述 |
|---|---|
| Kernel space | 操作系统的内核空间,保存操作系统内核的数据,用户进程无权访问该地址 |
| Stack(栈) | 用于实现程序中的函数调用,在下一节的程序运行中我们会详细了解栈的工作方式 |
| Heap(堆) | 为了保存在程序运行时(而非编译时)产生的全局变量注6 |
| Memory Map | 磁盘空间到内存的映射,可以像操作内存中的数据一样操作磁盘中的数据 |
5. 运行
开始执行
操作系统jmp到进程的第一条指令并不是main方法,而是别的代码。这些代码负责初始化main方法执行所需要的环境并调用main方法执行,运行这些代码的函数被称为入口函数或者入口点(Entry Point)。
一个程序的执行过程如下:
- 操作系统在创建进程之后,jmp到这个进程的入口函数
- 入口函数对程序运行环境进行初始化,包括堆、I/O、线程、全局变量的构造,等等
- 入口函数在完成初始化之后,调用main函数,开始执行程序的主体
- main函数执行完毕之后返回到入口函数,入口函数进行清理工作,最后通过系统调用结束进程
函数调用
栈用于维护函数调用的上下文,函数调用是通过栈完成的。
栈本身是一个容器,它的特性是FILO。通过上面的Linux内存分布图我们可以知道,内存中的栈是向下增长的。在x86中esp寄存器用于保存当前进程的栈顶的地址,push元素到栈中,esp中的值减小;从栈中pop元素,esp中的值增大。
栈为每一个函数调用维护了其所需要的一些信息,为每个函数所维护的信息部分叫做栈帧(Stack Frame),栈被分割为很多个栈帧。每一个栈帧保存了一个函数的如下信息
- 函数的参数和返回地址
- 临时变量,包括非静态局部变量和编译生成的其它临时变量
- 保存的上下文
一个函数被调用时将会有如下操作
- 把所有的参数压入栈中,有些参数也可以不压栈而通过寄存器进行传递
- 把当前指令的下一条指令的地址压入栈中
- 跳转到函数体执行
当一个函数被调用完毕之后,esp减小到上面的步骤2中的数据的位置,从栈中pop该指令地址,jmp到该指令继续执行。
堆(Heap)与内存管理
堆是一块巨大的内存,程序可以在堆中申请内存,这些内存在被程序主动放弃之前都可以随意使用。上图中黄色部分的堆我们在这里把它称为传统堆内存,Linux的堆内存由传统堆和Memory Map Segment共同组成。
Linux下的 brk() 和 mmap() 系统调用都可以用于申请堆内存,它们获取堆内存的方式分别如下
- brk 是将 program brk 向高地址推,以此来获取新的传统堆内存空间
- mmap 是在 Memory Map Segment 中找一块空闲的内存空间
但是我们一般不会直接使用系统调用,而是使用库函数来申请堆内存,我们一般使用glibc中的malloc函数来申请内存,它会根据申请内存的大小的不同而使用不同的实现
如果申请的内存小于128k
- 首先查看传统堆内存中是否有足够的空闲内存,如果有足够的空闲内存则直接分配给用户程序而不需要经过系统调用
- 如果传统堆中空闲内存不足则调用
brk系统调用增大传统堆以获取新的内存分配给用户程序 - 如果被 free 的内存位于 program brk 处,则调用
brk系统调用减小堆大小 - 如果被 free 的内存位于传统堆内部,则库函数记录下被释放空间的位置和大小,之后再有新的内存申请时可以优先的从传统堆的空闲内存中分配空间,而不需要再次调用
brk系统调用
如果申请的内存大于128k
- 使用
mmap系统调用申请内存 mmap所申请内存的释放使用munmap系统调用来实现
系统调用
操作系统负责实现对计算机系统资源的管理,用户程序无权直接使用系统资源。用户程序想要使用系统资源就必须调用操作系统所提供的接口,操作系统提供的接口叫做系统调用。
x86 CPU提供了4个特权级,Linux用到了其中的两个特权级,在Linux中分别叫内核态和用户态,内核态的特权级比用户态高。操作系统的内核(上图中最高位的kernel space)运行在内核态,用户程序无权访问内核态的数据,用户程序想要调用内核中的函数就必须要使用系统调用。
x86下使用中断(interrupt)来发送信息给CPU,一旦CPU收到了中断信息,就会停止执行当前任务转而根据中断编号去执行中断处理函数。中断处理函数由操作系统实现,一般来说每个中断编号都有自己的中断处理函数,这些中断处理函数组成了一个中断向量表,中断向量表由操作系统负责实现并管理。中断可以是由硬件产生的,例如键盘按下、鼠标点击等等;中断也可以由软件产生,x86 下 0x80 中断就是由软件触发的,0x80 中断是实现系统调用的核心。
用户程序调用系统调用的过程如下:
- 用户程序先根据调用惯例注7把中断处理函数所需要的参数保存在指定的寄存器中,例如
eax寄存器就应该保存系统调用的编号,eax = 1对应系统调用exit,eax = 2对应fork,等等 - 参数设置完毕之后,用户程序执行
int 0x80指令,CPU收到中断信息 - CPU将控制权限交给操作系统内核,进程的栈从用户栈切换到内核栈注8
- 中断向量表中 0x80 号中断的中断处理函数开始执行
- 中断处理函数从寄存器
eax中获取到系统调用编号,根据系统调用编号找到指定的系统调用函数 - 系统调用函数从约定好的寄存器中获取所需参数,系统调用函数根据参数开始执行
- 系统调用执行完毕后,将系统调用的结果存放在用户程序有权访问的区域(寄存器或内存)
- 系统调用返回,将控制权重新交给用户程序
- 用户程序从指定区域获取系统调用的结果,系统调用结束
用户写C语言时并不会手动的调用系统调用,它们一般都被封装在库函数中。例如 printf 函数就是对系统调用 write 的封装,下面我们就手动的调用 write 系统调用来实现向标准输出打印字符的功能。
相较于gcc支持的AT&T和Intel格式的汇编,我更喜欢NASM汇编的语法,下面是使用NASM实现的向标准输出打印字符串的汇编代码
global _start ; _start是一个符号(.symbol),链接器会把其作为entry point
; 数据段
section .data
buffer db 'hello, system call', 10, 0 ; buffer,10是换行符,0是字符串结束
length db 20 ; buffer的长度
; 代码段
section .text
_start:
mov eax, 4 ; 4,write系统调用
mov ebx, 1 ; fd(文件描述符),1为标准输出
mov ecx, buffer ; buffer的地址
mov edx, [length] ; 根据地址从数据段获取buffer的长度
int 0x80 ; system call
mov eax, 1 ; 1,exit系统调用
mov ebx, 0 ; exit code
int 0x80 ; system call
把汇编代码保存为 print.asm 文件,之后执行以下命令执行打印操作
$ nasm -f elf64 print.asm -o print.o
$ ld print.o -o print
$ ./print
hello, system call
总结
操作系统和编译器之间联系的非常的紧密,ELF文件就是操作系统和编译器之间的一个纽带。除了操作系统和编译器之间的关系很紧密,操作系统和编译器与CPU和内存的关系也是十分的紧密:操作系统要负责内存的管理,而我们的程序的很大一部分操作也是与内存相关;至于CPU我们不仅要通过中断才能实现系统调用,操作系统本身也需要CPU的特权级来实现对内核的保护。
回顾历史我们就会发现,C语言就是为了Unix而被发明的,它们之间在发展的过程中也不断的互补与完善,这才有了我们今天所看到的联系的十分紧密的类Unix操作系统和C语言编译器。
注:
include文件有如下两种语法
#include <filename.h>:编译器会优先到一些默认的文件夹注2中去寻找该头文件,如果未能找到则在当前目录下继续查找#include "filename.h":编译器优先在当前目录下查找头文件,找不到再去默认的文件夹中进行查找
一般来说
/usr/include或/usr/local/include会被当做默认文件夹,在gcc中你也可以使用-I $include_path来指定被 include 文件的目录static对于全局变量只影响其可见性(默认其它文件可见,加了static就只有当前文件可见;function也是一样),对于局部变量只影响其保存区域。则我们可以得到如下的规则
- 未初始化的全局变量:.bss
- 已初始化的全局变量:.data
- 未初始化的局部静态变量:.bss
- 已初始化的局部静态变量:.data
- 未初始化的局部普通变量:stack
- 已初始化的局部普通变量:stack
要查看一个可执行文件所引用的动态链接库可以使用命令
ldd虚拟地址通过MMU的映射转化为物理地址,操作系统负责MMU的初始化,用户进程使用的都是虚拟地址。
如果把内存比作一个旅店,旅店共有100个房间,而操作系统就是旅店的老板。旅店不断地有旅行团来旅店住宿,旅店老板对每一个旅行团都宣称我们有100个房间,其中10个是员工宿舍,所以每个旅行团都有90个房间可以用。
旅行团的成员无法自己找到房间,必须要使用旅店提供的地图才能找到对应的房间,但其实每个旅行团手中的地图都是不一样的,这个地图保证客人绝对不会找到一个已经被别人使用的房间。一旦客人在房间已经睡着了,旅店老板就可能会把这个客人偷偷地运到旅店的一个隐蔽的仓库中去,这样这个房间又被空了出来,旅店老板可以继续把这个房间租给别人。(真是奸商啊)
一旦旅行团中有人开始找某个旅客,但是这个旅客已经被移到了仓库中,旅店老板就会赶紧把这个人从仓库中移回到某个房间中,然后改变地图,让同一个旅行团的人能成功的在房间中找到这个旅客。
为什么要有堆?为了保存程序在运行时产生的全局变量
- 数据段:只能保存在编译时产生的变量
- 栈:只能在当前方法内部保存变量
系统调用的调用惯例和函数调用有些类似,但是系统调用使用寄存器而不是栈作为参数传递的载体
因为系统调用本质上也是函数,在x86下既然是函数就需要用到栈。不过系统调用作为内核中的函数,为了防止用户程序访问,不应该使用用户空间的栈。因此我们需要在内核中也建立一个栈,这个栈专门用于系统调用函数的执行。每个进程都有一套栈,即用户栈和内核栈,在系统调用函数执行之前首先需要做用户栈到内核栈的切换,栈的切换很简单,只需要修改esp的值即可。
参考:
程序员的自我修养
https://github.com/1184893257/simplelinux
高级语言的编译:链接及装载过程介绍
golang语言编译的二进制可执行文件为什么比 C 语言大
Linux内存分配的原理–malloc/brk/mmap