TCP 协议的流量控制与 Linux 内核的 Scoket 缓冲区
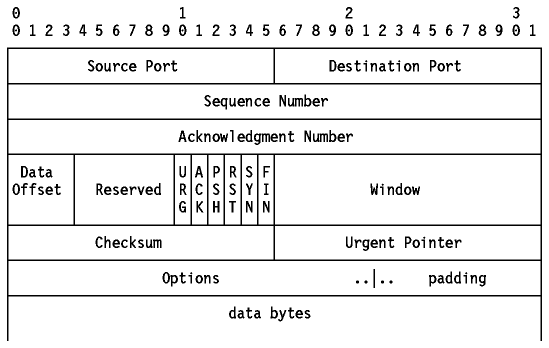
TCP 协议为了协调发送端和接受端的数据发送和接收速度,需要实现对流量的控制,这就是 TCP 协议的流量控制。TCP 报文的格式见下表,其中的Window部分叫做接收窗口,TCP 的流量控制就是通过它来实现的:
发送端发送的数据的类型
考虑到接收端的数据处理速度,发送端不能无节制的发送数据,发送端的数据可以分为以下 3 种类型:
- 已发送已确认,数据已经发送给接收端并且接收端已经发送了该数据的 ACK
- 已发送未确认,数据已经发送给接收端但是还未获取到接收端的确认信息
- 待发送数据,发送端已经准备好可以发送但是还没有发送的数据,这是我们接下来要重点讨论的数据
Linux 的读缓冲区和 TCP ACK 报文中的 Window
Liunx 在内核中有一个 socket 的读缓冲区,操作系统的 TCP 协议栈在接收到数据之后会把数据存放在这里,因为操作系统会为每一个 TCP 连接维护一个状态机,所以每一个连接都拥有自己的读缓冲区。读缓冲区的大小依据操作系统不同而不同,用户也可以自行设定其大小。假设发送端不断地向接收端发送数据,但是接收端的用户处理程序却没能及时的从读缓冲区中把数据读走,那么读缓冲区的数据就会越来越多。接收端会根据此连接读缓冲区的剩余可用空间来判断接收端还能接受多少数据,公式如下:
Window = MaxReadBuffer – ReadedBuffer
根据可接受数据的大小,操作系统会在回复给发送端的 ACK 报文中通过 Window 告知发送端接收端自己当前还能接受的数据量。
发送端如何根据 TCP ACK 报文中的 Window 控制流量
让我们回到发送端,发送端在发送完数据接收到接收端的 ACK 之后,可以从 ACK 中得到接收端设定的窗口大小,根据接收端设置的窗口大小,发送端需要计算得到自己还能发送多少数据给接收端。
得到了 Window 的大小之后,发送端知道自己还能够发送多少数据。最极端的情况下,接收端的用户程序一直没去读取读缓冲区的数据,那么读缓冲区的数据不断增加最终导致接收端的读缓冲区满,此时接收端会在 ACK 报文中把 Window 的大小设置为 0,发送端在发现接收端的 Window 为 0 之后就会停止向接收端发送数据。此时发送端当前连接的写缓冲区就不会再有数据被 TCP 协议栈取出,如果用户程序仍然在向这个连接发送数据,那么发送端的写缓冲区最终会满,此时write系统调用无法再继续写数据。此时write syscall分为两种情况:
- write 为阻塞:用户程序将被阻塞直到写缓冲区有足够的空间接受当前写入的数据,此时数据被写到写缓冲区内,write 方法返回;
- write 为非阻塞:直接报错,告诉用户当前连接不可写;
与上面类似,如果发送端一直没发数据,那么接收端的读缓冲区的数据会不断减少,此时接收端的用户程序在调用read syscall的时候也会分为两种情况:
- read 为阻塞:阻塞直到用户能从内核中读到足够的数据为止;
- read 为非阻塞:直接报错,告诉用户当前连接不可读;
顺便说一下,发送端在发现接收端的窗口为 0 之后,会每隔一段时间发送一个 Zero Window Probe(ZWP) 包给接收端,接收端在这个包 ACK 中告诉发送端当前接收端最新的 Window 大小,以避免发送端无止境的等待下去。
对于单个连接,我们可以用下图来了解 TCP 的流量控制与 Linux Socket 缓冲区之间的关系:
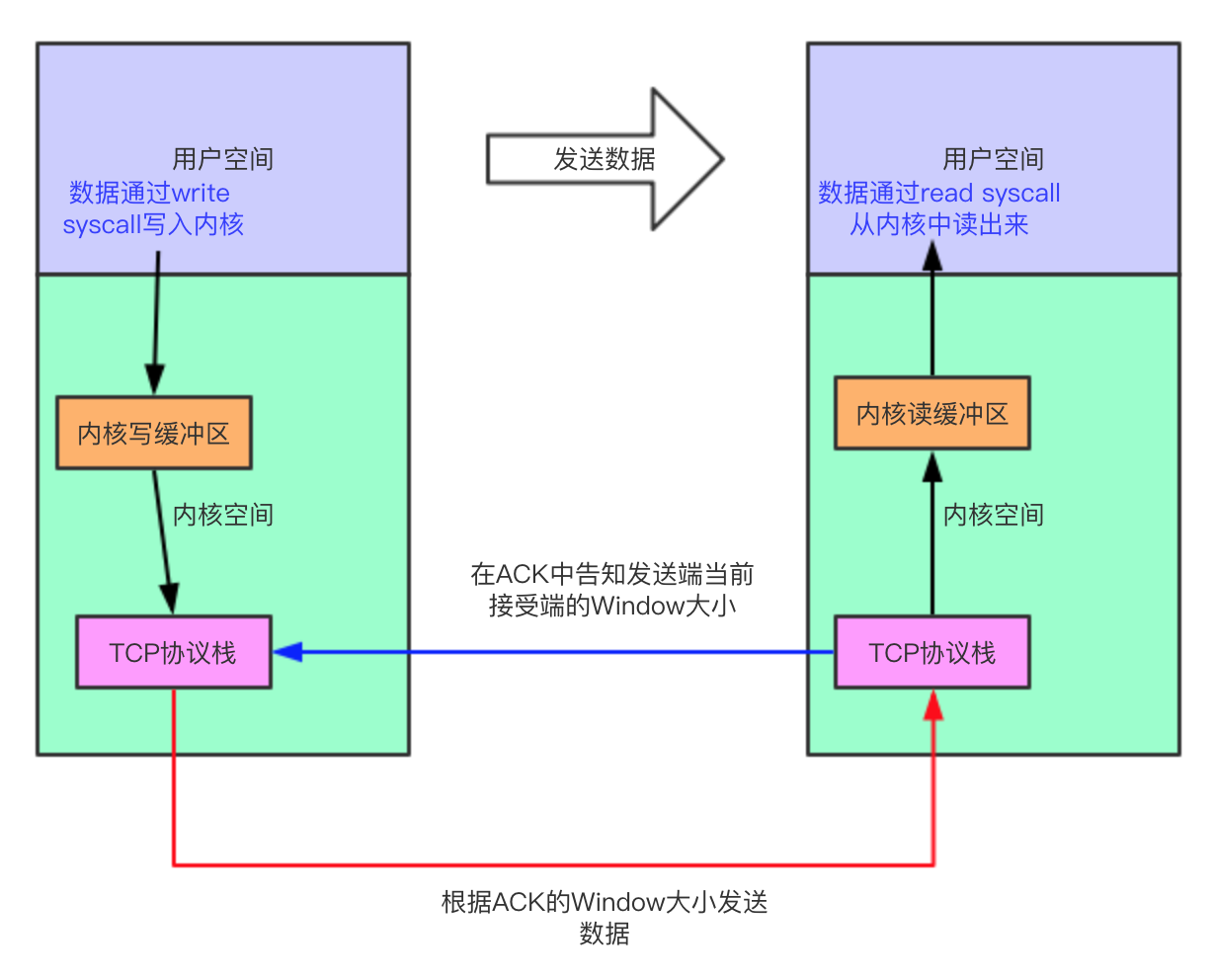
需要注意的是,我们在创建一个 TCP 连接的时候会有 client 和 server 上的概念。但是一旦当 TCP 连接创建完成,由于 TCP 是全双工的,所以我们上面所说的发送端和接收端都既可以是客户端也可以是发送端。当客户端发送数据的时候它就是发送端,当客户端接受数据的时候它就是接收端,服务端同理。
滑动窗口与 TCP 的拥塞控制
我们前面讲到了 TCP 协议的流量控制,流量控制是端到端的,即对发送端和接受端进行控制的操作。TCP 协议除了有对链路两端进行协商的流量控制之外,还有对中间链路上的数据包进行控制的拥塞控制。
我们举个例子注 1,假设战争时期后方向前线运送粮食。当粮食不断的运向前线,一段时间之后前线来信说前线粮食已经非常多了,不仅将士们吃不完,连粮仓都放不下了,此时后端就要放慢粮食的运送速度或者停止向前线运送粮食,这就是流量控制。
还是运送粮食的例子,假设后方运送到前方的粮食在路上总是被人抢走或者因为天气原因丢失,又或者运送粮食的车过多影响了军队的其它物资的运送,那么后方就要开始考虑减少粮食的运送,这就是拥塞控制。
关于拥塞控制就不多说了,拥塞控制本身还是比较复杂的,也涉及到了很多的算法,有兴趣的可以自行查阅资料了解相关的内容。
注 1:例子参考了刘超的相关教程