计算机的计算(二) - 下推自动机
本文是计算机的计算系列的第二篇。
1. 下推自动机
自带栈的有限状态机叫作下推自动机(PushDown Automaton,PDA)。
上面给出了下推自动机的概念,那么为什么我们要在有限自动机的基础上给其增加一个栈来构建下推自动机呢?其根本原因在于有限状态机本身无法存储数据,而加上了栈之后的下推自动机则具有了数据存储能力。具有了存储能力之后,下推自动机的计算能力相较于有限自动机得到了进一步的增强。
我们已经知道,有限自动机在进行状态转移的时候,需要读取一个输入,然后根据当前状态已经输入来进行状态转移。下推自动机在进行状态转移的时候同样要依赖于当前状态和输入,不过,因为下推自动机有了栈的概念,所以在进行状态转移的时候我们还需要一点别的东西——读栈和写栈操作。例如下图这样的一个下推自动机:
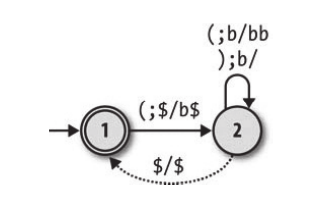
我们可以把这个下推自动机用这样的转移列表列出来,注意这里的 $ 符号,因为栈为空的状态并不是很好判断,所以我们添加了这个字符来代表栈为空,也就是说栈的最底部永远应该保持有 $ 这个字符。最下面的虚线代表着当栈为空且状态为2时(我们使用虚线来代表不需要有输入的转移情形,即自由移动),此时不需要任何输入,栈会自动的弹出 $ 然后再压入 $,随后状态从2变为1。
| 当前状态 | 输入字符 | 转移状态 | 栈顶字符(读入/弹出) | 压入字符 |
|---|---|---|---|---|
| 1 | ( | 2 | $ | b$ |
| 2 | ( | 2 | b | bb |
| 2 | ) | 2 | b | 不压入 |
| 2 | 无输入 | 1 | $ | $ |
相对于有限自动机,下推自动机只是增加了一个入栈和出栈的操作,可以说并不复杂,但是需要提醒的一点是:对于下推自动机,栈顶的元素也是转移的规则之一。怎么理解这句话呢?下面我通过一个小例子来说明。
有如下两个转移规则
| 当前状态 | 输入字符 | 转移状态 | 栈顶字符(读入/弹出) | 压入字符 |
|---|---|---|---|---|
| 1 | a | 2 | x | $ |
| 1 | a | 3 | y | $ |
当在状态1读到输入a的时候,此时并不能决定到底要转移到那一个状态,而是要根据此时的栈顶元素(x或是y)来判断要进行哪一种的转移操作,所以说栈顶元素也是转移的规则之一。《计算的本质》中是这样描述这个特性的:
在某种程度上,下推自动机还能控制自己。在规则和栈之间有一个反馈环——栈的内容影响机器应该遵守的规则,而按照某个规则执行也会影响栈的内容——这允许PDA在栈中存储一些信息,这些信息可以影响它将来的执行。
因为下推自动机是有限自动机的扩充,所以下推自动机也分为确定性下推自动机和非确定性下推自动机,下面将会详细介绍。
2. 确定性下推自动机
什么是确定性?即 无冲突、无遗漏。
- 对于无冲突,我们只要保证下推自动机在进行状态转移的时候不会产生模棱两可的规则即可;
- 而无遗漏这个要求操作起来就比较的棘手,因为下推自动机一般很难把所有的转移规则都覆盖到,所以一般的做法是忽略这个约束并允许DPDA(确定性下推自动机,Deterministic PushDown Automaton)只定义完成工作所需的规则,并且假定一台DPDA在没有规则可用时将进入停滞状态。
了解DPDA的定义后,就开始使用Python来模拟一个下推自动机吧,代码实现如下:
1 | """ |
虽然代码的实现看上去挺复杂的,但是我们只需要牢记两点:
- 下推自动机只是有限自动机增加了一个栈而已,所以我们只是增加了栈的压入和弹出操作
- 下推自动机的转移规则还需要指定栈顶元素,栈顶元素不一样的不能算为同样的转移规则
3. 非确定性下推自动机
在介绍非确定性下推自动机之前,我们写来了解一下使用非确定性下推自动机有什么好处。观察下面这张图,这是一个用来检测一个输入是否是回文的确定性下推自动机。
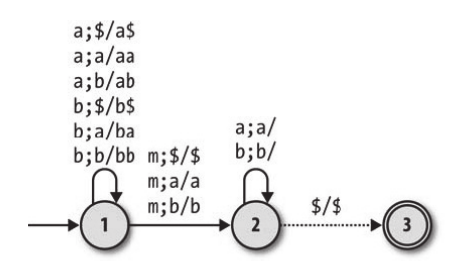
- 处于状态1且输入了a或者b的时候,每输入一个输入就会在栈顶把这个输入加上去(和之前不一样,我们在这里把直接把输入入栈了,也就是把输入和栈联系了起来。在之前,输入和栈内元素我们都是区分开来的);
- 在输入了
m之后,又会把栈内元素根据输入顺序弹出来(也就是当栈顶为a时,我们必须输入a,之后a被弹出,下一个元素继续进行同样的操作)。
在有了这种机器之后,我们就能识别出类似于 babbamabbab 这样的回文了。但是我们还需要一个额外的 m 来进行分割的操作,这样感觉并不是很优美。我们可以使用非确定性下推自动机来完成同样的操作(出于简单考虑,该自动机只支持偶数个字母的判断):
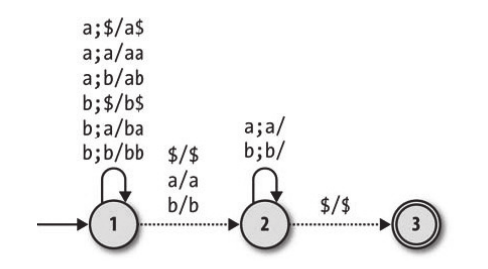
上面这个机器除了状态1到状态2的转移操作和之前的DPDA不一样,其余完全一样。也就是说从状态1到状态2的转移不需要任何的确定性的约束,这种没有确定性约束的下推自动机叫作非确定性下推自动机。下面就是一个非确定性下推自动机的模拟:
1 | """ |
我们同样使用集合来保存非确定性下推自动机的配置的可能情况,具体的思想可以参考DFA到NFA的转化方式。
4. 不等价
我们已经了解了任意的一个NFA都可以转化为一个与其等价的DFA,那么任意一个NPDA都可以转化为一个与其等价的DPDA吗?非常遗憾,答案是否定的。
所以不幸的是,我们的 NPDA 模拟的行为并不像一台 DPDA,也不存在 NDPA 到 DPDA
的算法。无标记的回文问题就是这样一个例子,NPDA 能完成这个问题,但 DPDA 不能,
因此非确定性下推自动机确实比确定性的能力要强。